YOLOv2和YOLO9000:更好、更快、更强的目标检测器.
YOLOv2是YOLO的增强版本。YOLO9000则是在YOLOv2的基础上使用联合数据集进行训练,该数据集结合了COCO检测数据集和ImageNet的前9000个类。
1. YOLOv2
YOLOv2相比于YOLO进行了很多改进,引入了许多提高检测精度的训练和测试方法:
- 应用BatchNorm:为所有卷积层增加BatchNorm,能够显著改善网络的收敛性;
- 增大图像分辨率:在微调模型时使用更大的分辨率能够提高检测性能;
- 引入anchor:YOLOv2并不是像YOLO一样直接预测每个特征位置的边界框坐标,而是在图像中引入anchor框,预测anchor框的位置和类别。进一步解耦边界框回归和类别分类,尽管mAP轻微下降,但是能显著提高召回率;
- 通过k-means设置anchor尺寸:YOLOv2通过对训练数据集中标注框执行k-means寻找合适的anchor尺寸,其中边界框之间的距离定义为:$dist(x,c_i)=1-IoU(x,c_i)$。最佳anchor尺寸的数量$k$可以通过肘部法则确定。
- 直接执行边界框回归:YOLOv2假设预测边界框离对应anchor的中心距离不太远。给定anchor尺寸$(p_w,p_h)$及其对应的栅格左上角坐标$(c_x,c_y)$,模型预测边界框偏移量$(t_x,t_y,t_w,t_h)$,则预测预测边界框及其置信度得分计算为:

- 增加细粒度特征:YOLOv2通过跳跃连接把网络早期的细粒度特征传递给最后一个输出层,这个改进使表现提高了$1\%$;
- 多尺度训练:为了使模型对不同尺度的图像输入具有鲁棒性,每$10$次batch对输入图像的尺寸进行随机采样。YOLOv2对图像特征进行$32$倍下采样,因此图像采样尺寸应为$32$的倍数;
- 轻量级模型:为了提高推理速度,YOLOv2采用了一个轻量级卷积网络DarkNet-19,该网络包括$19$个卷积层和$5$个最大池化层,并把$1\times 1$卷积和池化层插入到$3\times 3$卷积之间。
2. YOLO9000
由于在图像上人工标注边界框比直接标注图像类别的成本要高得多,因此本文提出了一种结合小型目标检测数据集与大型图像分类数据集联合训练目标检测模型的方法。在联合训练过程中,如果输入图像来自分类数据集,则反向传播只会计算分类损失。
YOLO9000结合了COCO检测数据集和ImageNet的排名前9000个类。通常目标检测数据集的目标类别数量更少,并且类别细粒度低。而图像分类数据集的类别细粒度更高。为了融合ImageNet数据集的前$9000$个类别与COCO数据集的$80$个类别,YOLO9000通过WordNet建立了一个层次化树结构,使得细粒度低的标签作为根,细粒度高的标签作为叶。
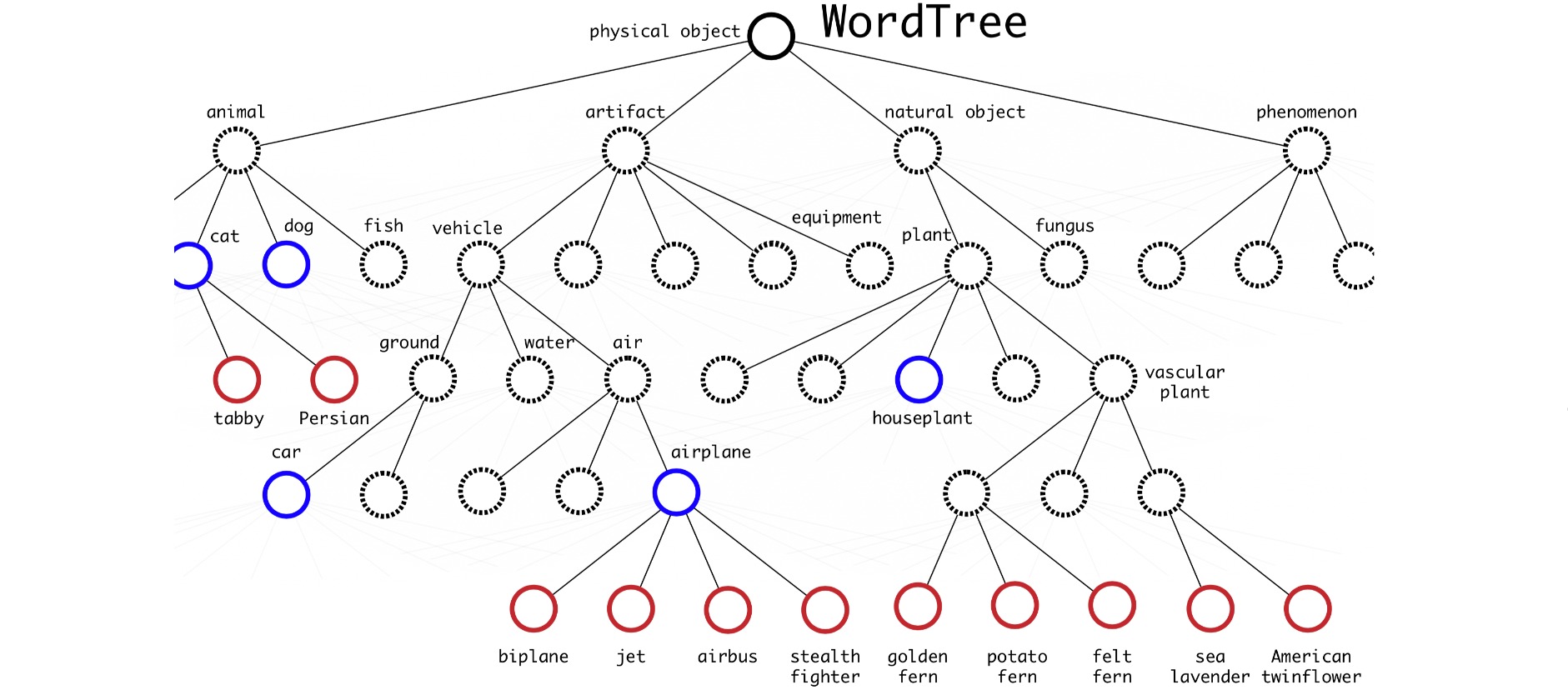
为了预测类别叶节点的概率,可以遵循从节点到根的路径:
Pr("persian cat" | contain a "physical object")
= Pr("persian cat" | "cat")
Pr("cat" | "animal")
Pr("animal" | "physical object")
Pr(contain a "physical object") # confidence score.


