YOLO:统一的实时目标检测.
YOLO模型是目前最知名的单阶段目标检测算法之一,它的基本思想是用卷积网络实现滑动窗口。当一张图像喂入卷积网络后,可以得到尺寸缩小的特征映射,比如$7×7$的映射。映射的每一个特征像素都能对应到原图像中的一个子区域,假设原图像的这个子区域内含有目标,则通过网络把相关信息编码到特征映射的对应区域上。

在原始的网络中,每一个子区域预设一些边界框用来检测该区域可能出现的目标,由此可以看出,单阶段的检测方法在每个子区域都会预测很多边界框,因此所处理的候选区域是非常密集的,所以会出现大量的负样本,造成目标检测中正负样本的比例极其不均衡,这也是影响单阶段目标检测算法的主要问题。
⚪ YOLO的工作流程
YOLO模型的工作流程如下:
- 在通用的图像分类任务(如$1000$类的ImageNet)上预训练一个卷积神经网络(如AlexNet, VGGNet, ResNet);
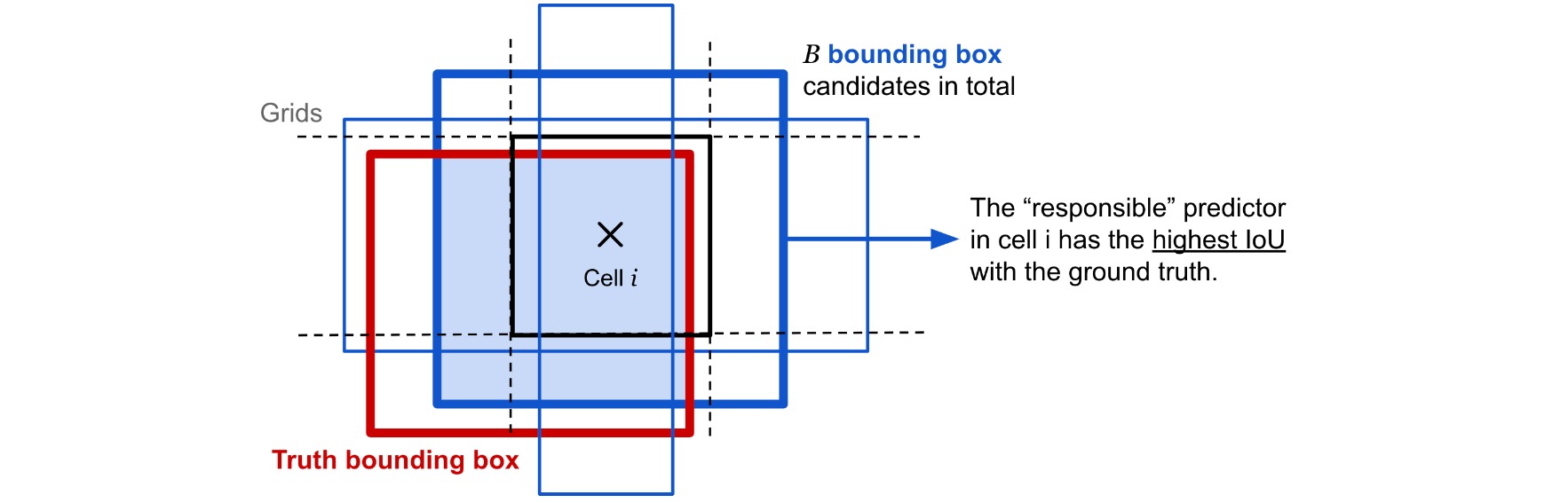
- 把图像划分成$S\times S$个网格。如果有目标的中心落入某一网格中,则该网格负责检测出该目标。每个网格预测$B$个边界框的位置和置信度得分,以及以边界框中存在目标为条件的目标类别概率。
- 边界框的坐标定义为中心位置相对于网格中心的偏移量以及宽度和高度$(x,y,w,h)$,并被图像宽度和高度归一化,因此取值均为$(0,1]$;
- 置信度得分显示了网格中存在目标的可能性,相当于存在目标的概率乘以目标边界框与Ground Truth之间的IoU;
- 如果网格中存在目标,则模型进一步预测该网格中目标属于每个类别$c_i,i=1,…,K$的条件概率$P(\text{目标类别为}c_i|\text{存在目标})$;
- 综上所述,每张图像包含$S\times S \times B$个边界框,每个边界框包含四个位置坐标和一个置信度得分;图像的每个网格还要预测$K$个条件概率。则对于每一张输入图像,网络的输出特征尺寸为$S\times S \times (5B+K)$。
⚪ YOLO的网络结构
YOLO模型采用的DarkNet结构上与Inception网络相似,主要把Inception模块替换为$1\times 1$卷积和$3\times 3$卷积。

网络输入$448\times 448$的图像,进行$64$倍下采样后得到$7\times 7$的特征映射,其特征维度是$1024$。经过全连接层后输出特征维度是$(5B+K)=30$。

⚪ YOLO的损失函数
YOLO的损失函数包括边界框位置的定位损失和条件类别概率的分类损失,这两个损失都是通过平方误差定义的。
\[\begin{aligned} \mathcal{L}_{\mathrm{loc}} & =\lambda_{\text {coord }} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{i j}^{\mathrm{obj}}\left[\left(x_i-\hat{x}_i\right)^2+\left(y_i-\hat{y}_i\right)^2+\left(\sqrt{w_i}-\sqrt{\hat{w}_i}\right)^2+\left(\sqrt{h_i}-\sqrt{\hat{h}_i}\right)^2\right] \\ \mathcal{L}_{\mathrm{cls}} & =\sum_{i=0}^{S^2} \sum_{j=0}^B\left(\mathbb{1}_{i j}^{\mathrm{obj}}+\lambda_{\text {noobj }}\left(1-\mathbb{1}_{i j}^{\mathrm{obj}}\right)\right)\left(C_{i j}-\hat{C}_{i j}\right)^2+\sum_{i=0}^{S^2} \sum_{c \in \mathcal{C}} \mathbb{1}_i^{\mathrm{obj}}\left(p_i(c)-\hat{p}_i(c)\right)^2 \\ \mathcal{L} & =\mathcal{L}_{\mathrm{loc}}+\mathcal{L}_{\mathrm{cls}} \end{aligned}\]超参数$\lambda_{coord}$控制边界框的定位损失的权重;$\lambda_{noobj}$控制减少不包含目标的边界框的置信度损失权重,由于绝大多数边界框都不包含目标,因此降低背景边界框的损失权重是十分必要的。实验中设置$\lambda_{coord}=5,\lambda_{noobj}=0.5$。
\(\mathbb{1}_i^{\mathrm{obj}}\)是网格$i$中是否存在目标的指示函数,当有Ground Truth的中心落入网格时取值为$1$。当\(\mathbb{1}_i^{\mathrm{obj}}=1\)时,网格中与Ground Truth框IoU最大的边界框$j$设置\(\mathbb{1}_{ij}^{\mathrm{obj}}=1\),其余为$0$。
作为一个单阶段的目标检测器,YOLO速度极快,但由于候选边界框的数量有限,它对于识别形状不规则的目标或一组小目标的精度较差。


