全景特征金字塔网络.
FPN在实例分割中取得巨大成功后,作者提出了Panoptic FPN来完成语义分割任务,结果发现FPN在语义分割中能够提供轻巧的网络结构、快速的分割速度、精确的分割结果。

为了实现从FPN中输出语义结果的功能,作者将FPN金字塔每一层的输出合并为单个输出。以最深层($1/32$的特征图)为例,经过3次卷积和2倍上采样后,输出为$1/4$大小的特征图。其余层也经过类似的方法生成类似的结果,然后相加成一个输出。经过卷积和上采样后生成语义结果。
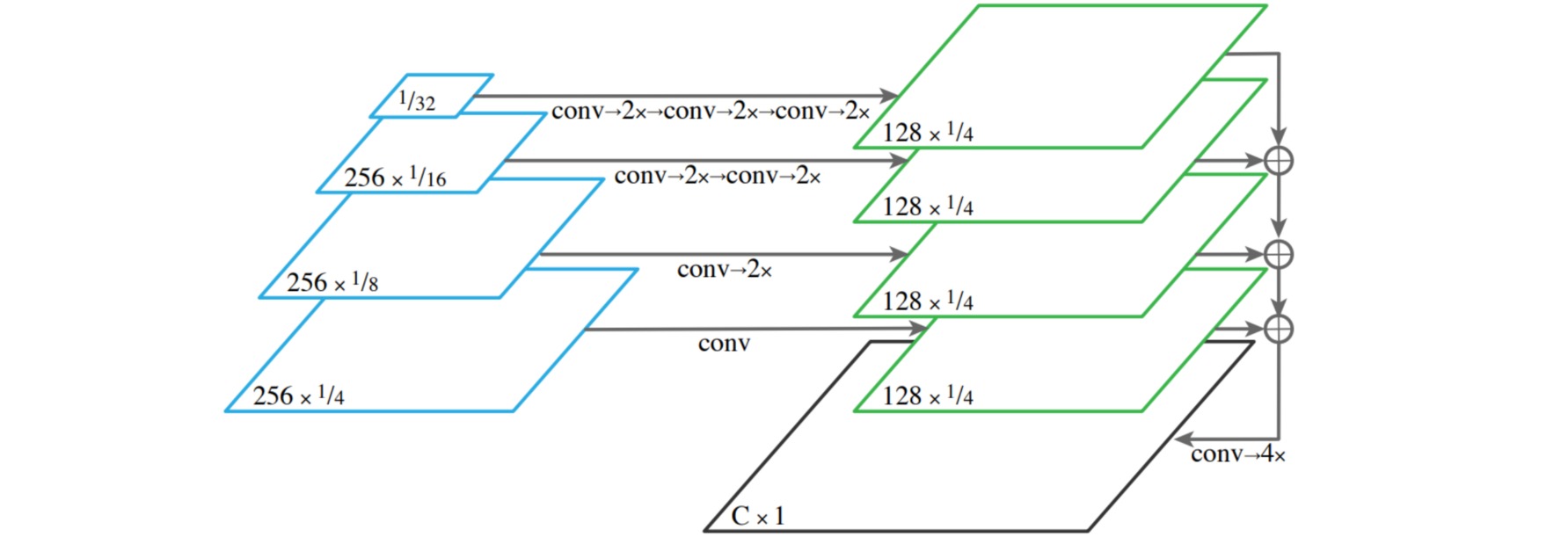
与Unet直接将各对应层的结果在通道上相加不同,FPN在每一层的连接中间加了卷积和上采样,这样主干网络的下采样层也可以获得更自由的结果,更加灵活。
class FPNHead(nn.Module):
def __init__(self, feature_strides=[4, 8, 16, 32], in_channels=[256, 512, 1024, 2048], channels=256):
super(FPNHead, self).__init__()
self.in_channels = in_channels
self.channels = channels
assert len(feature_strides) == len(self.in_channels)
assert min(feature_strides) == feature_strides[0]
self.feature_strides = feature_strides
self.scale_heads = nn.ModuleList()
for i in range(len(feature_strides)):
head_length = max(
1,
int(np.log2(feature_strides[i]) - np.log2(feature_strides[0])))
scale_head = []
for k in range(head_length):
scale_head.append(
nn.Conv2d(
self.in_channels[i] if k == 0 else self.channels,
self.channels,
3,
padding=1))
if feature_strides[i] != feature_strides[0]:
scale_head.append(
nn.Upsample(
scale_factor=2,
mode='bilinear',
align_corners=True))
self.scale_heads.append(nn.Sequential(*scale_head))
def forward(self, inputs):
x = inputs[-len(inputs):]
output = self.scale_heads[0](x[0])
for i in range(1, len(self.feature_strides)):
# non inplace
output = output + nn.functional.interpolate(
self.scale_heads[i](x[i]),
size=output.shape[2:],
mode='bilinear',
align_corners=True)
return output
class FPNNet(nn.Module):
def __init__(self, num_classes):
super(FPNNet, self).__init__()
self.num_classes = num_classes
# backbone返回每个模块的输出特征
self.backbone = ResNet.resnet50(replace_stride_with_dilation=[1,2,4])
self.Head = FPNHead()
self.cls_seg = nn.Sequential(
nn.Upsample(scale_factor=4,
mode='bilinear',
align_corners=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, num_classes, 3, padding=1)
)
def forward(self, x):
x = self.backbone(x)
x = self.Head(x)
x = self.cls_seg(x)
return x


