Sequence to sequence.
序列到序列(Sequence to sequence, Seq2Seq)模型是一种序列生成模型,能够根据一个随机长度的输入序列生成另一个随机长度的序列。
Seq2Seq模型通常是用循环神经网络实现的。根据序列的基本单位不同,可以分为词(word)级别的模型和字符(character)级别的模型。
Seq2Seq模型可用于语音识别、文本摘要、对话系统、图像标题生成、机器翻译、阅读理解等任务。
本文目录:
- 模型介绍
- 生成过程:贪婪搜索, 束搜索
- 曝光偏差与计划采样
- 条件Seq2Seq模型
- 指针网络
1. 模型介绍
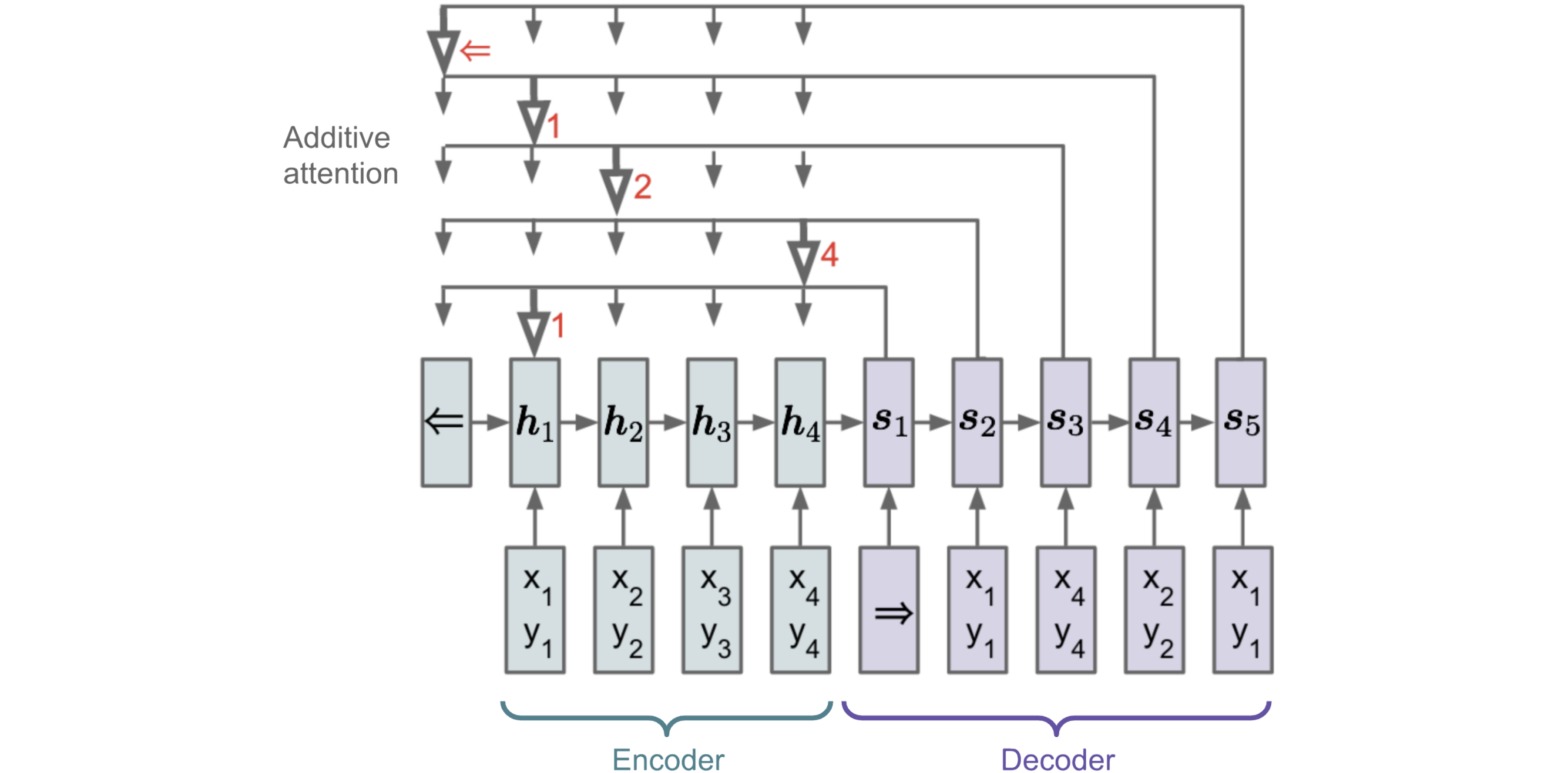
Seq2Seq模型通常采用编码器-解码器(Encoder-Decoder)结构:
- 编码器处理输入序列,并将信息压缩成固定长度的上下文向量(context vector,也称为句子嵌入sentence embedding或thought向量);通常希望该向量能够很好地概括整个输入序列的含义。
- 解码器用上下文向量初始化,以序列地生成输出结果。早期的工作仅使用编码器的最后状态作为解码器的初始状态。

这种Seq2Seq模型的缺点是:
- 编码向量的容量问题,输入序列的信息很难全部保存在一个固定维度的向量中;
- 当序列很长时,由于循环神经网络的长程依赖问题,容易丢失早期输入序列的信息。
为解决上述问题,引入注意力机制。
训练时解码器将每一个单词/字符的one-hot向量或词嵌入向量作为输入,对应的下一个单词/字符作为输出;并最小化预测值和真实值的交叉熵。生成时解码器对于每一个输入随机采样一个输出,作为下一个输入。

其中\(<BOS>\)标志序列起始(begin of sequence),\(<EOS>\)标志序列结束(end of sequence)。
2. 生成过程
训练好的Seq2Seq模型可用于序列生成。
(1) 贪婪搜索
当使用Seq2Seq模型生成一个最可能的序列时,生成过程是一种从左到右的贪婪式搜索过程。在每一步都生成最可能的词,直到生成符号\(<EOS>\)。
这种生成方法可能不是最优的; 如下图,最优的序列是绿色序列,但却生成了红色序列:

(2) 束搜索
一种常用的减少搜索错误的启发式方法是束搜索(Beam Search)。
在每一步中,生成$K$个最可能的前缀序列,其中$K$为束的大小(Beam Size),是一个超参数。
如下图,若选定$2$,则每次在生成的序列中选择概率最大的前$2$个:

束的大小$K$越大,束搜索的复杂度越高,但越有可能生成最优序列。
在实际应用中,束搜索可以通过调整束大小$K$来平衡计算复杂度和搜索质量之间的优先级。
3. 曝光偏差与计划采样
Seq2Seq模型在训练时的输入是固定的序列(真实数据);生成时每一步输入上一步输出采样的结果(模型生成数据)。这会造成训练和测试(生成)数据的不匹配(mismatch)。
在生成时,如果采集到训练时不存在的序列,会导致错误传播,使得后续生成的序列也会偏离真实分布。这个问题称为曝光偏差(Exposure Bias)。

为了缓解曝光偏差问题,可以在训练时混合使用真实数据和模型生成数据,这种策略称为计划采样(Scheduled Sampling)。
在每一步,以$ε$的概率使用真实数据,以$1-ε$的概率使用模型生成数据。

如果一开始训练时的$ε$过小,模型相当于在噪声很大的数据上训练,会导致模型性能变差,并且难以收敛。
因此,一个较好的策略是在训练初期赋予$ε$较大的值,随着训练次数的增加逐步减小$ε$的取值。
计划采样的一个缺点是过度纠正,即在每一步中不管输入如何选择,目标输出依然是来自于真实数据。这可能使得模型预测一些不正确的序列。
4. 条件Seq2Seq模型
有时候不希望Seq2Seq模型生成随机的序列,因此在序列生成时引入一些条件conditions。如在图像标注时把图像内容作为条件,在对话系统中把提问者的问题作为条件。
这时可以把条件信息作为RNN每一次时间步的输入。

5. 指针网络
- paper:Pointer Networks
在一些序列生成任务中,比如排序问题或旅行商人问题,输出序列的维度是由输入序列的长度确定的,无法提前指定。
如下图所示,输入$10$个点的坐标序列,输出边界点的坐标。此时输出应该是一个$10$维的0/1向量。这类问题无法直接使用Seq2Seq模型解决。

指针网络(pointer network)是一种特殊的Seq2Seq模型,它的输出元素指向输入序列的位置(索引下标)。输入是长度为$N$的向量序列\(X=(x_1,...,x_N)\);输出是长度为$M$的下标序列\(C_{1:M}=(c_1,...,c_M), c_m \in [1, N]\)。对于每一个输出时间步,通过注意力机制选择一个输入位置。指针网络在实现时,要在输入序列首端加上一个END标志。
指针网络中每个时间步的输出概率可以表示为:
\[p(c_m| c_1,...,c_{m-1},x) = \text{softmax}(v^T \tanh(W[s_{m-1};h]))\]

