PCT:点云Transformer.
最近几年transformer在NLP、CV等领域都取得了很大的成功。作者利用了transformer能够处理无序数据的特点,将transformer应用到点云的处理上,其整体架构采用一种编码器-解码器结构:对于编码器,点云数据先经过一个输入嵌入模块,然后通过一系列的注意力模块并且连接每个模块的输出,最后再经过一个全连接层得到点云的特征。对于解码器,根据任务不同其结构不同。
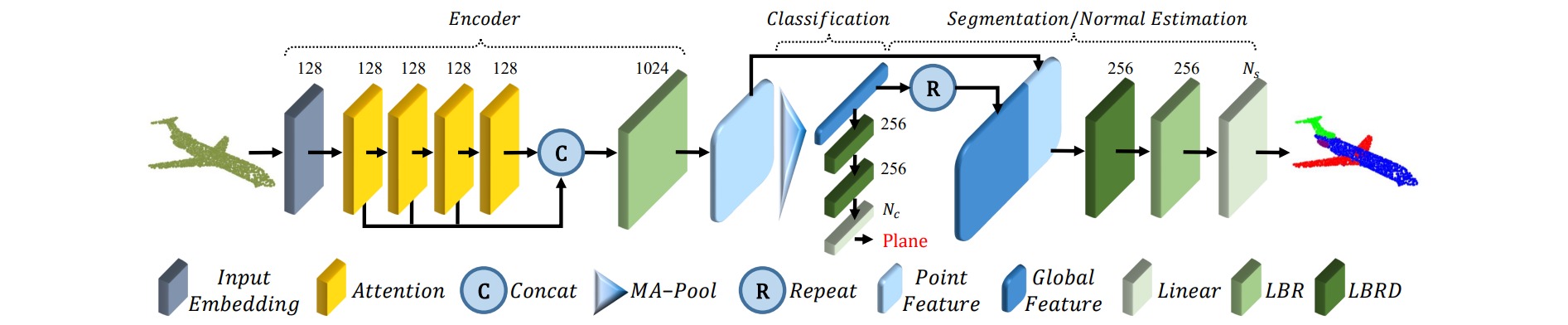
根据网络结构由简入繁,作者把encoder分为三个版本:NPCT(Naive PCT)、SPCT(Simple PCT)、PCT。
(1)Naive PCT
NPCT(Naive PCT)的输入嵌入模块采用两层LBR (Linear-BN-ReLU),注意力模块直接采用Transformer中的标准自注意力层。
(2)Simple PCT

SPCT(Simple PCT)将NPCT结构里面的SA(Self-Attention)改变为OA(Offset-Attention),OA的结构如图所示。
OA在SA的基础上做了两个调整。第一个调整是对应用注意力机制后的特征与输入特征做element-wise的差值。该操作启发于图卷积里拉普拉斯矩阵$L=D-E$替代邻接矩阵,这种调整使得网络不只聚合节点附近的邻接信息,并且还可以把节点自身的信息也考虑进去。为了说明做element-wise的差值之后可以有近似拉普拉斯矩阵的效果,作者给出了一个推导过程:
\[\begin{aligned} \mathbf{F}_{i n}-\mathbf{F}_{s a} & =\mathbf{F}_{i n}-\mathbf{A} \mathbf{V} \\ & =\mathbf{F}_{i n}-\mathbf{A} \mathbf{F}_{i n} \mathbf{W}_v \\ & \approx \mathbf{F}_{i n}-\mathbf{A} \mathbf{F}_{i n} \\ & =(\mathbf{I}-\mathbf{A}) \mathbf{F}_{i n} \approx \mathbf{L} \mathbf{F}_{i n} \end{aligned}\]第二个调整是在normalization这一步,在原始的transformer为了计算attention map的时候为了防止softmax输入数值过大导致梯度消失,会先进行缩放。作者把这个缩放系数取消,直接softmax得到attention map,然后在第二个维度上做L1归一化。这样做之后能让attention weights更加集中,让网络将更多的注意力集中到点云的局部区域,并且能减少噪声的干扰。
class SA_Layer(nn.Module):
def __init__(self, channels):
super(SA_Layer, self).__init__()
self.q_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)
self.k_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)
self.q_conv.weight = self.k_conv.weight
self.q_conv.bias = self.k_conv.bias
self.v_conv = nn.Conv1d(channels, channels, 1)
self.trans_conv = nn.Conv1d(channels, channels, 1)
self.after_norm = nn.BatchNorm1d(channels)
self.act = nn.ReLU()
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
x_q = self.q_conv(x).permute(0, 2, 1) # b, n, c
x_k = self.k_conv(x) # b, c, n
x_v = self.v_conv(x) # b, c, n
energy = torch.bmm(x_q, x_k) # b, n, n
attention = self.softmax(energy)
attention = attention / (1e-9 + attention.sum(dim=1, keepdim=True))
x_r = torch.bmm(x_v, attention) # b, c, n
x_r = self.act(self.after_norm(self.trans_conv(x - x_r)))
x = x + x_r
return x
(3)PCT

在SPCT基础上作者改进了输入嵌入模块。point embedding只擅长学习点云的全局特征,容易忽略点云局部信息,因此作者引入PointNet++中的局部信息聚合网络,提出了neighbor embedding结构。
Input Embedding的整体架构是两个全连接层+两个SG(sampling and grouping)模块,SG模块既可以对特征进行下采样,又可以聚合邻域信息。
SG模块首先对输入特征进行下采样,并且通过最近邻算法找出每个采样点的k邻域,然后对于每个邻域中的点跟采样点做一个差值,然后将这个差值跟采样点连接起来通过两层全连接层,最后通过最大池化得到每个采样区域的局部特征。差值代表了局部区域的一些几何信息,而采样点代表了这个局部区域的中心点(也就是这个局部区域的空间位置),将这两种信息连接之后能让网络进一步聚合局部信息。
from .PointNetpp_module import sample_and_group
class Local_op(nn.Module):
def __init__(self, in_channels, out_channels):
super(Local_op, self).__init__()
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size=1, bias=False)
self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm1d(out_channels)
self.bn2 = nn.BatchNorm1d(out_channels)
def forward(self, x):
b, n, s, d = x.size() # torch.Size([32, 512, 32, 6])
x = x.permute(0, 1, 3, 2)
x = x.reshape(-1, d, s)
batch_size, _, N = x.size()
x = F.relu(self.bn1(self.conv1(x))) # B, D, N
x = F.relu(self.bn2(self.conv2(x))) # B, D, N
x = F.adaptive_max_pool1d(x, 1).view(batch_size, -1)
x = x.reshape(b, n, -1).permute(0, 2, 1)
return x
class Point_Transformer_Last(nn.Module):
def __init__(self, channels=256):
super(Point_Transformer_Last, self).__init__()
self.conv1 = nn.Conv1d(channels, channels, kernel_size=1, bias=False)
self.conv2 = nn.Conv1d(channels, channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm1d(channels)
self.bn2 = nn.BatchNorm1d(channels)
self.sa1 = SA_Layer(channels)
self.sa2 = SA_Layer(channels)
self.sa3 = SA_Layer(channels)
self.sa4 = SA_Layer(channels)
def forward(self, x):
batch_size, D, N = x.size()
x = F.relu(self.bn1(self.conv1(x))) # [B, D, N]
x = F.relu(self.bn2(self.conv2(x))) # [B, D, N]
x1 = self.sa1(x)
x2 = self.sa2(x1)
x3 = self.sa3(x2)
x4 = self.sa4(x3)
x = torch.cat((x1, x2, x3, x4), dim=1) # [B, 4D, N]
return x
class Pct(nn.Module):
def __init__(self, output_channels=40):
super(Pct, self).__init__()
self.conv1 = nn.Conv1d(3, 64, kernel_size=1, bias=False)
self.conv2 = nn.Conv1d(64, 64, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(64)
self.gather_local_0 = Local_op(in_channels=64+3, out_channels=128)
self.gather_local_1 = Local_op(in_channels=128+3, out_channels=256)
self.pt_last = Point_Transformer_Last()
self.conv_fuse = nn.Sequential(nn.Conv1d(1280, 1024, kernel_size=1, bias=False),
nn.BatchNorm1d(1024),
nn.LeakyReLU(negative_slope=0.2))
self.linear1 = nn.Linear(1024, 512, bias=False)
self.bn6 = nn.BatchNorm1d(512)
self.dp1 = nn.Dropout(p=0.5)
self.linear2 = nn.Linear(512, 256)
self.bn7 = nn.BatchNorm1d(256)
self.dp2 = nn.Dropout(p=0.5)
self.linear3 = nn.Linear(256, output_channels)
def forward(self, x):
xyz = x.permute(0, 2, 1) # B, D, N
batch_size, _, _ = x.size()
x = F.relu(self.bn1(self.conv1(x))) # B, D', N
x = F.relu(self.bn2(self.conv2(x))) # B, D', N
x = x.permute(0, 2, 1) # B, N, D'
new_xyz, new_feature = sample_and_group(xyz, x, 512, 0.15, 32)
feature_0 = self.gather_local_0(new_feature)
feature = feature_0.permute(0, 2, 1)
new_xyz, new_feature = sample_and_group(new_xyz, feature, 256, 0.2, 32)
feature_1 = self.gather_local_1(new_feature) # B, D', N
x = self.pt_last(feature_1)
x = torch.cat([x, feature_1], dim=1)
x = self.conv_fuse(x)
x = F.adaptive_max_pool1d(x, 1).view(batch_size, -1)
x = F.leaky_relu(self.bn6(self.linear1(x)), negative_slope=0.2)
x = self.dp1(x)
x = F.leaky_relu(self.bn7(self.linear2(x)), negative_slope=0.2)
x = self.dp2(x)
x = self.linear3(x)
return x


