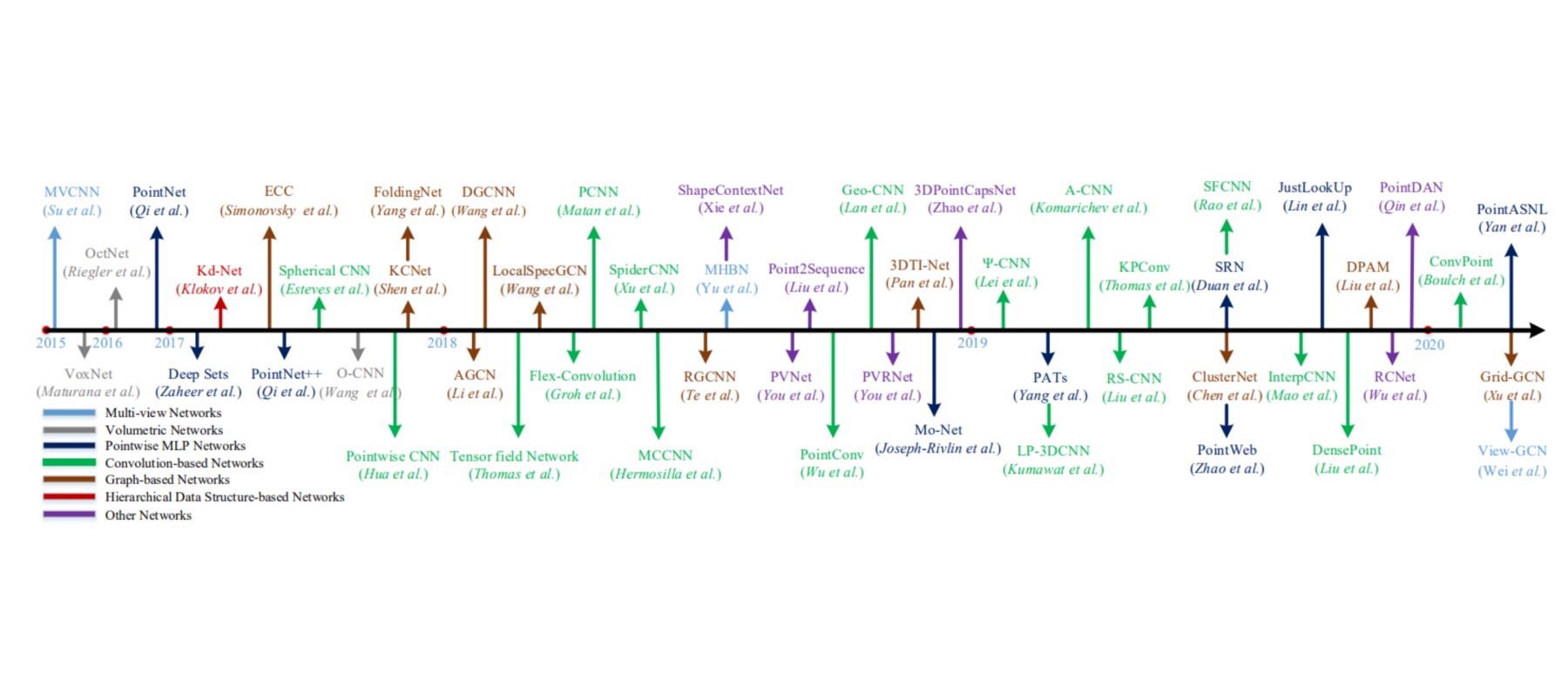
用于3D形状识别的多视角卷积神经网络.
本文提出了一种用于3D形状识别的多视角卷积神经网络MVCNN,用物体的三维数据从不同“视角”所得到的二维渲染图作为原始的训练数据,用经典的二维图像卷积网络进行训练。相比于用三维数据直接训练,二维卷积网络成熟度、速度都是很大的优势,能有远超三维数据的效果。
从3D立体形状中,由一个渲染引擎渲染得到一系列该3D形状多视角的2D图像。由这些2D图像每张得到一个图像特征描述算子,再用某种投票或者排序机制对这些描述算子排序,以此使用这些独立的描述算子来做图像识别任务。
3D形状数据是以多边形网格的格式存储的。使用Phone reflection model方法来由多边形网格产生渲染图。为了产生3D形状的多视角渲染图,需要设定一个“视角”(虚拟相机)来产生网格的渲染图。作者试验了两种视角初始化:
- 假设输入的3D形状是按照一个恒定的轴(Z轴)正直的摆放的。这种情况下每个3D形状产生了12张不同视角下的渲染图(每30度产生一个2D视角渲染图)。相机“拍摄”时与水平面有30度的水平角,且径直指向3D网格数据的“中心”(所有的网格面中心的权重加和,权重是各个网格面的面积)。
- 通过围绕3D形状生成20面体,将“相机”放在20面体的顶点上。每个相机在其“点位”上有前后左右四个方向(旋转0,90,180,270度方向),每个“点位”上能够得到4个视角图。因此最后共有80个视角图。
在现在图像处理硬件上,完成所有的视角点的每一张网格2D渲染图消耗不超过10万毫秒的时间(100秒)。
每一张视角图可以提取一个图像描述子(特征),作者使用了一个简单的CNN网络,网络结构是5层卷积层+3个全连接层,最后是Softmax分类层。倒数第二层由一个ReLU激活层输出的4096维特征被用作图像描述算子。整个网络先在ImageNet图像集上进行预训练,之后用之前采集到的多视角图像进行微调。
MVCNN能够融合多视角2D图像产生的特征,以便综合这些信息,形成一个简单、高效的3D形状描述子。
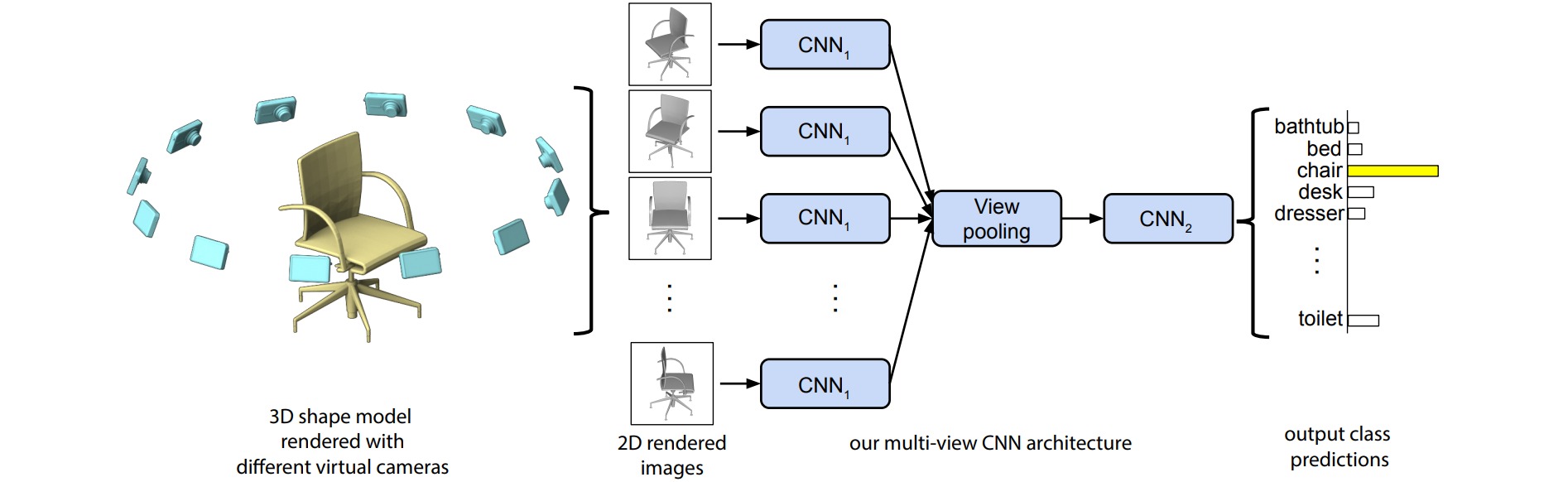
同一个3D形状的每一张视角图像各自独立地经过第一段的CNN1卷积网络,在一个View-Pooling层进行“聚合”。之后再送入剩下的CNN2卷积网络。整个网络第一部分的所有分支共享相同的CNN1的参数。在View-pooling层中,逐元素取不同视角特征的最大值。
作者在ModelNet数据集上进行实验评估,ModelNet数据集包含127,915个3D CAD模型,662个类别,40个标注好的子类,共12,311个形状。结果表明MVCNN在点云分类与检索任务中均超越了之前的方法。