通过WiFi信号实现密集的人体姿态估计.
- paper:DensePose From WiFi
近些年使用 2D 和 3D 传感器(如 RGB 传感器、LiDAR 和穿墙雷达)进行人体姿态估计取得了很大进展。但是这些传感器在技术上和实际使用中都存在一些限制。首先是成本高,个体使用者往往承担不起昂贵传感器的费用。其次这些传感器在日常使用中功率过高。
在实际场景中,狭窄的视野、遮挡和恶劣的照明条件会对基于 RGB 相机的方法造成严重影响,隐私问题也阻碍了在非公共场所使用这些技术。本文作者提出,在某些情况下 WiFi 信号可以作为 RGB 图像的替代方案来进行人体感知。照明和遮挡对用于室内监控的 WiFi 设备影响不大,并且有助于保护个人隐私,所需的相关设备成本较低。
作者使用 3 个 WiFi 发射器和 3 个对应的接收器在多人的杂乱环境中检测和复原密集人体姿态对应关系。很多 WiFi 路由器(如 TP-Link AC1750)都有 3 根天线,因此实际使用中只需要 2 个路由器。


作者设计了一种基于 WiFi 的密集姿态估计网络架构,能够利用 WiFi 信号生成人体表面的 UV 坐标。接收原始原始 CSI( Channel-state-information,表示发射信号波与接收信号波之间的比值 )信号后分别对振幅和相位信号进行噪声过滤和拟合。

然后将处理过的 CSI 数据通过模态转换网络从 CSI 域转换到空间域。具体过程为分别对振幅和相位信号进行编码后融合并重构为$24 \times 24$的特征,并通过一个编码器-解码器网络转换到图像域中的$1280 \times 720 \times 3$的特征。

在图像域中获得$1280 \times 720 \times 3$的场景特征表示后,采用 DensePose-RCNN 网络架构来预测人体 UV 图,把 2D 图像转换为 3D 人体模型。该网络使用 ResNet-FPN 作为主干,从$1280 \times 720 \times 3$图像特征图中提取空间特征。然后将输出输送到区域提议网络。对于每一个对齐的提议特征,通过关键点检测头和密集姿态头分别提取关键点特征和人体表面特征。为了更好地利用不同来源的互补信息,通过 refinement 单元对两个特征进行融合与重构。

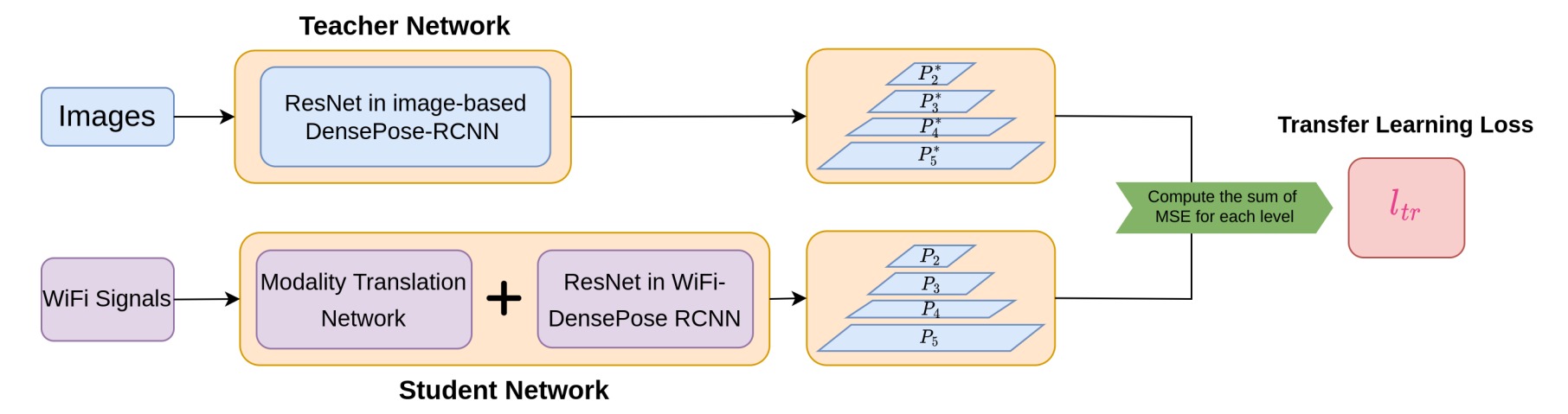
为了提高训练效率,解决缺乏标签的问题,将一个基于图像的 DensPose 网络迁移到基于 WiFi 的网络中。首先训练了一个基于图像的 DensePose-RCNN 模型作为教师网络,学生网络由模态转换网络网络和 WiFi-DensePose RCNN 组成,并最小化学生模型与教师模型生成的多层特征图之间的差异。
实验的评估指标有两个。分别是评估关键点性能的Average precision (AP)和评估人体表面性能的DensePose Average precision (dpAP)。
实验结果显示基于 WiFi 的方法得到了很高的 AP@50 值,为 87.2,这表明该模型可以有效地检测出人体的大致位置。但AP@75 相对较低,值为 35.6,这表明人体细节的估计效果较差。

结果显示 dpAP・GPS@50 和 dpAP・GPSm@50 值较高,但 dpAP・GPS@75 和 dpAP・GPSm@75 值较低。这表明模型在估计人体躯干的姿态方面表现良好,但在检测四肢等细节方面仍然存在困难。

与基于图像的方法相比,基于 WiFi 的模型 AP-m 值与 AP-l 值的差异相对较小。作者认为这是因为离相机远的目标在图像中占据的空间范围更少,这导致关于这些目标的信息更少。而 WiFi 信号包含了整个场景中的所有信息,对拍摄对象的位置具有鲁棒性。


作者进一步进行了一些消融实验,结果表明预处理CSI中的相位信息、增加关键点的监督训练和采用基于图像的迁移学习都能够有效地提高方法的性能。


最后作者测试了在unseen环境下的泛化性能。


作者汇报了一些预测错误的例子。对于训练集中很少出现的人体姿态,基于WiFi的模型会产生偏差,并预测出错误的身体部位。此外当环境中同时出现三个或更多个目标时,基于WiFi的模型从整个CSI信号中提取每个目标的详细信息将更具挑战性。



