Ultralytics YOLOv8:实时目标检测和图像分割模型的最新版本.
- paper:Ultralytics YOLOv8
YOLOv8 是 Ultralytics 公司开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。YOLOv8 在以前 YOLO 版本的成功基础上并引入了新的功能和改进,具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,相比 YOLOV5 大部分模型推理速度变慢了。

YOLOv8 算法的核心特性和改动可以归结为如下:
- 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
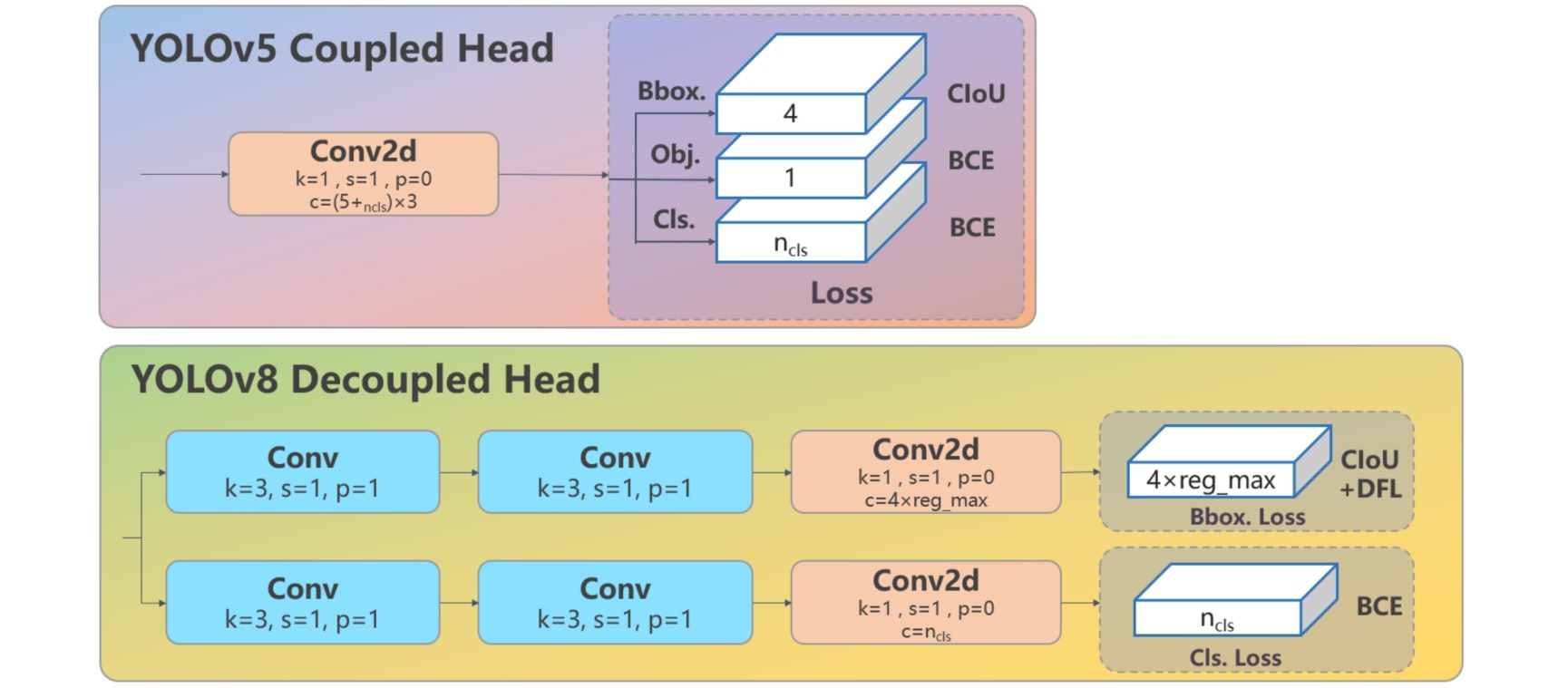
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
1. 模型结构设计

YOLOv8 相比 YOLOv5 在骨干网络和 Neck 的具体变化为:
- 第一个卷积层的 kernel 从 6x6 变成了 3x3
- 所有的 C3 模块换成 C2f,多了更多的跳层连接和额外的 Split 操作
- 去掉了 Neck 模块中的 2 个卷积连接层
- Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
- N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数
Head 部分从原先的耦合头变成了解耦头,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free:
2. 损失函数计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。
现代目标检测器大部分都会在正负样本分配策略上面做文章,考虑到动态分配策略的优异性,YOLOv8 算法直接引用了 TOOD。 TOOD 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
\[t=s^\alpha+u^\beta\]$s$ 是标注类别对应的预测分值,$u$ 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
- 对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics
- 对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支:
- 分类分支:采用 BCE Loss
- 回归分支:和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
3. 训练策略
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:

考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。
YOLOv8 的训练策略和 YOLOv5 最大区别就是模型的训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:

4. 模型推理过程
YOLOv8 的推理过程和 YOLOv5 唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox。
以 COCO 80 类为例,假设输入图片大小为 640x640,YOLOv8 中实现的推理过程示意图如下所示:

- bbox 积分形式转换为 4d bbox 格式:对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
- 维度变换:YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。 将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
- 解码还原到原图尺度:分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
- 阈值过滤:遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
- 还原到原图尺度和 nms:基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。


