DyNet:加速卷积神经网络的动态卷积.
正如已有网络剪枝技术所提,CNN中的卷积核存在相关性。本文作者首先对现有网络的卷积核进行了相关性分析和可视化:

结果表明大部分网络的输出激活有较强的相关性。作者提出可以通过多个卷积核的动态融合来替代多个相关卷积核的协同组合,因此设计了如下动态卷积。
动态卷积的目标是学习一组核系数并用于融合多个卷积核为一个动态核。作者采用可训练的系数预测模块预测系数,然后采用动态生成模块进行卷积核融合。
系数预测模块可以基于图像内容预测融合系数。该模块由全局平均池化与全连接层构成。

动态生成模块根据预测的系数对固定的卷积核进行融合。融合过程是分别在每个输出通道上进行的,若应用$K$个固定卷积核,特征的输出通道数为$C_{out}$,则权重向量的长度为$KC_{out}$。

在训练过程中,由于每张输入图像的动态卷积核都是不一样的,所以在一个batch里并行计算是困难的。因此作者提出在训练阶段基于预测的系数融合特征,而不是融合卷积核,而这两种方式是等价的:
\[\begin{aligned} y(p_0) &= \sum_{p_n \in \mathcal{R}} (\sum_{k=1}^K \pi_k(x)w_k(p_n)) \cdot x(p_0+p_n) \\ &= \sum_{k=1}^K \pi_k(x)(\sum_{p_n \in \mathcal{R}} w_k(p_n)\cdot x(p_0+p_n) ) \\ &= \sum_{k=1}^K \pi_k(x)y_k(p_0) \end{aligned}\]作者给出了mobileNet、shuffleNet、resnet18、resnet50上增加动态卷积的方式:

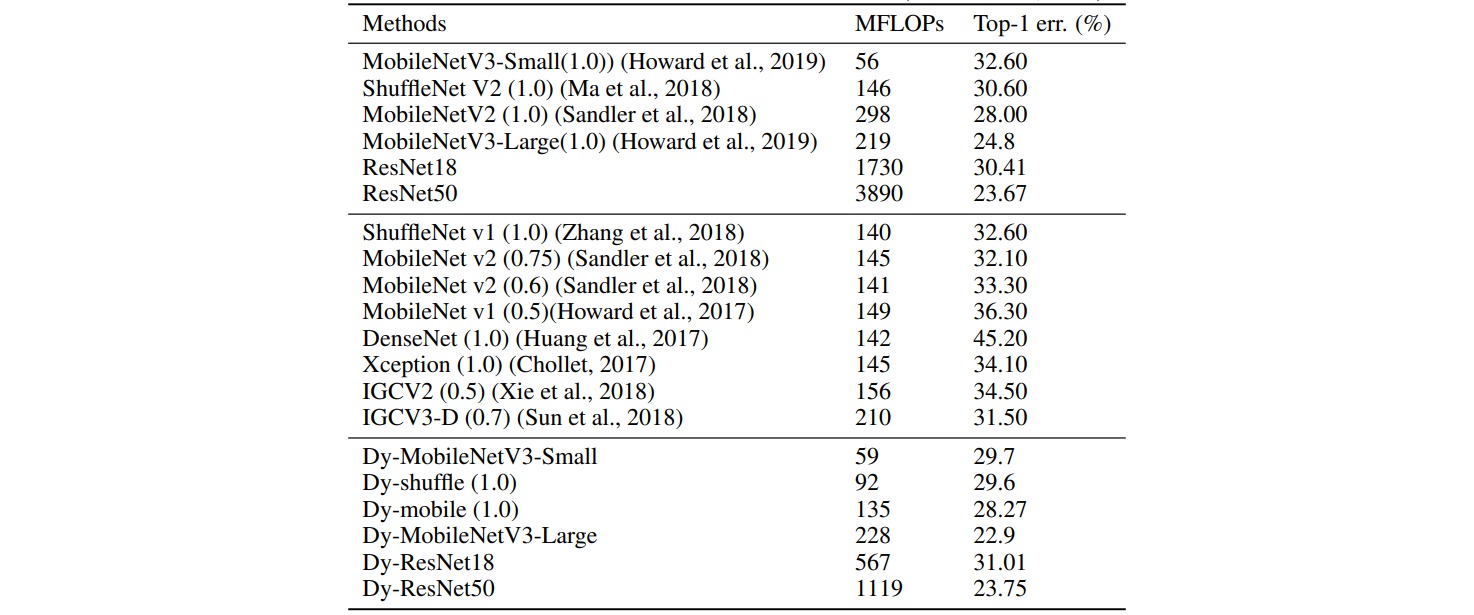
实验结果表明,在相近的计算量下,Dy-MobileNetv3-small的性能更高;在性能接近的情况下,Dy-ResNet50的计算量减少了三分之二。
相关性的可视化也表明,引入动态卷积后卷积核之间的相关性减少。

import functools
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn.modules.conv import _ConvNd
from torch.nn.modules.utils import _pair
from torch.nn.parameter import Parameter
class _coefficient(nn.Module):
def __init__(self, in_channels, num_experts, out_channels, dropout_rate):
super(_coefficient, self).__init__()
self.num_experts = num_experts
self.dropout = nn.Dropout(dropout_rate)
self.fc = nn.Linear(in_channels, num_experts*out_channels)
def forward(self, x):
x = torch.flatten(x)
x = self.dropout(x)
x = self.fc(x)
x = x.view(self.num_experts, -1)
return torch.softmax(x, dim=0)
class DyNet2D(_ConvNd):
r"""
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple, optional): Stride of the convolution. Default: 1
padding (int or tuple, optional): Zero-padding added to both sides of the input. Default: 0
padding_mode (string, optional): ``'zeros'``, ``'reflect'``, ``'replicate'`` or ``'circular'``. Default: ``'zeros'``
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
groups (int, optional): Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional): If ``True``, adds a learnable bias to the output. Default: ``True``
num_experts (int): Number of experts per layer
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros', num_experts=3, dropout_rate=0.2):
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(DyNet2D, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
# 全局平均池化
self._avg_pooling = functools.partial(F.adaptive_avg_pool2d, output_size=(1, 1))
# 注意力全连接层
self._coefficient_fn = _coefficient(in_channels, num_experts, out_channels, dropout_rate)
# 多套卷积层的权重
self.weight = Parameter(torch.Tensor(
num_experts, out_channels, in_channels // groups, *kernel_size))
self.reset_parameters()
def _conv_forward(self, input, weight):
if self.padding_mode != 'zeros':
return F.conv2d(F.pad(input, self._padding_repeated_twice, mode=self.padding_mode),
weight, self.bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def forward(self, inputs): # [b, c, h, w]
res = []
for input in inputs:
input = input.unsqueeze(0) # [1, c, h, w]
pooled_inputs = self._avg_pooling(input) # [1, c, 1, 1]
routing_weights = self._coefficient_fn(pooled_inputs) # [k,]
kernels = torch.sum(routing_weights[: , :, None, None, None] * self.weight, 0)
out = self._conv_forward(input, kernels)
res.append(out)
return torch.cat(res, dim=0)


