上下文编码器:通过修补进行特征学习.
本文设计了一种用于上下文的像素预测的无监督特征学习方法上下文编码器(Context Encoders),能够根据周围像素生成任意图像区域。通过构造重构损失和对抗损失,能够获得更清晰的图像修补效果。

上下文编码器采用一种编码器-解码器结构,编码器接收masked输入图像,提取图像特征;解码器将图像特征解码为缺失的图像区域。

在编码器和解码器之间采用通道全连接层(Channel-wise fully-connected layer),通过完全独立地连接每个通道,能够减少网络参数。
1. 网络结构
上下文编码器被设计为两种形式。一种形式适用于固定大小比例、固定形状的修复($128 \times 128$到$64 \times 64$):

class Generator(nn.Module):
def __init__(self, channels=3):
super(Generator, self).__init__()
def downsample(in_feat, out_feat, normalize=True):
layers = [nn.Conv2d(in_feat, out_feat, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2))
return layers
def upsample(in_feat, out_feat, normalize=True):
layers = [nn.ConvTranspose2d(in_feat, out_feat, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_feat, 0.8))
layers.append(nn.ReLU())
return layers
self.model = nn.Sequential(
*downsample(channels, 64, normalize=False),
*downsample(64, 64),
*downsample(64, 128),
*downsample(128, 256),
*downsample(256, 512),
nn.Conv2d(512, 4000, 1),
*upsample(4000, 512),
*upsample(512, 256),
*upsample(256, 128),
*upsample(128, 64),
nn.Conv2d(64, channels, 3, 1, 1),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
另一种适用于不固定大小,不固定形状的修复(原图大小到原图大小):
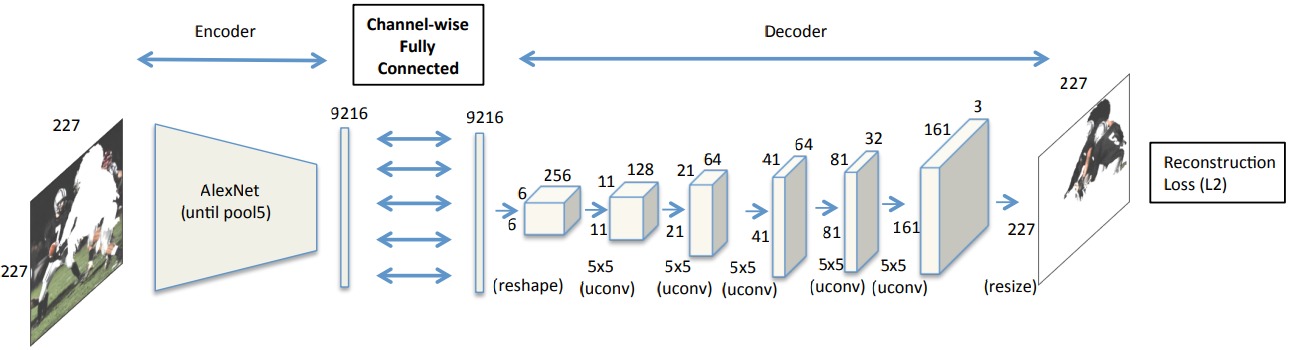
2. 损失函数
上下文编码器的损失函数包括L2重构损失和对抗损失。
L2重构损失捕获缺失区域的整体结构,使修补后的区域与周围具有结构一致性;由于L2损失倾向于多种填充方式的平均结果,所以产生的图像比较模糊。
在训练时随机产生输入图像的二值化的掩码$\hat{M}$(1表示缺失区域,0表示输入像素),用$F$表示上下文编码器,则重构损失表示为:
\[\mathcal{L}_{rec}(x) = ||\hat{M} \odot (x-F((1-\hat{M})\odot x))||_2^2\]def apply_random_mask(img, mask_size):
img_size = img.shape
"""Randomly masks image"""
y1, x1 = np.random.randint(0, img_size - mask_size, 2)
y2, x2 = y1 + mask_size, x1 + mask_size
masked_part = img[:, y1:y2, x1:x2]
masked_img = img.clone()
masked_img[:, y1:y2, x1:x2] = 1
return masked_img, masked_part
pixelwise_loss = torch.nn.L2Loss()
gen_parts = generator(masked_imgs)
g_pixel = pixelwise_loss(gen_parts, masked_parts)
对抗损失则在修补的图像区域上建立:
generator = Generator()
discriminator = Discriminator()
adversarial_loss = torch.nn.BCELoss()
# 定义优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
for epoch in range(n_epochs):
for i, imgs in enumerate(dataloader):
masked_img, masked_part = apply_random_mask(imgs)
# 构造对抗标签
valid = torch.ones(masked_parts.shape[0], 1).requires_grad_.(False)
fake = torch.zeros(masked_parts.shape[0], 1).requires_grad_.(False)
gen_parts = generator(masked_imgs)
# 训练判别器
optimizer_D.zero_grad()
# 计算判别器的损失
real_loss = adversarial_loss(discriminator(masked_parts), valid)
fake_loss = adversarial_loss(discriminator(gen_parts.detach()), fake) # 此处不计算生成器的梯度
d_loss = (real_loss + fake_loss) / 2
# 更新判别器参数
d_loss.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
g_loss = adversarial_loss(discriminator(gen_parts), valid)
g_loss += g_pixel
g_loss.backward()
optimizer_G.step()
Context Encoders的完整pytorch实现可参考PyTorch-GAN。


