通过Anchor引导实现区域提议.
anchor-based的目标检测方法需要预设anchor,anchor设置的好坏对结果影响很大,因为anchor本身不会改变,所有的预测值都是基于anchor进行回归;一旦anchor设置不太好,那么效果肯定影响很大。
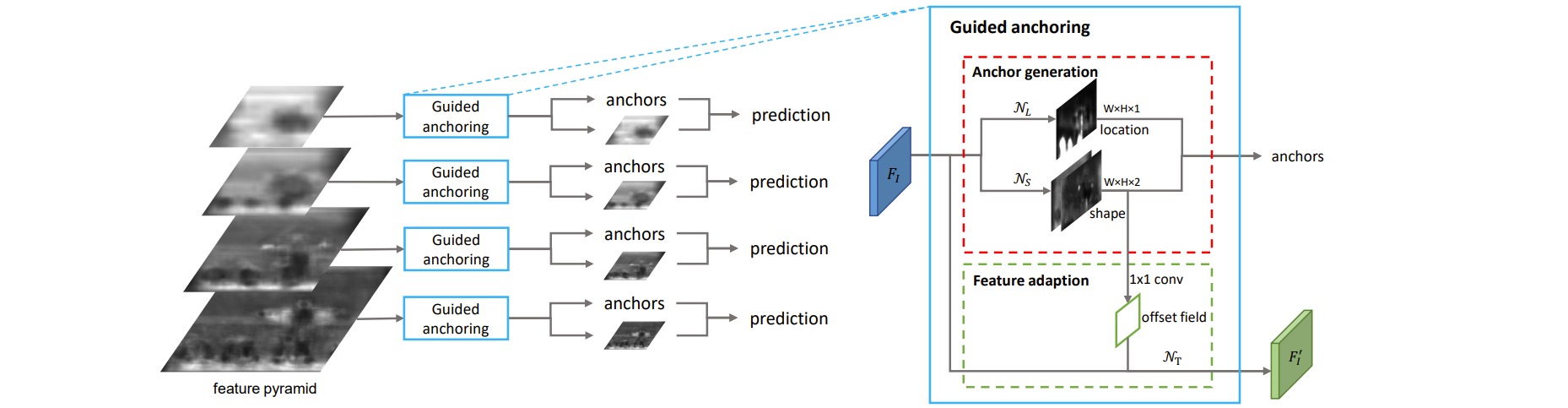
不管是one stage还是two-stage,都是基于语义信息来预测的,在bbox内部的区域激活值较大,这种语义信息正好可以指导anchor的生成。本文通过图像特征来指导 anchor 的生成。通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的动态anchor。
作者采用了一种可以直接插入当前anchor-based网络中进行anchor动态调整的做法,而不是替换掉原始网络结构。以retinanet为例,在预测xywh的同时,新增两条预测分支,一条分支是loc (batch,anchor_num * 1,h,w),用于区分前后景,目标是预测哪些区域应该作为中心点来生成 anchor,是二分类问题;另一条分支是shape (batch,anchor_num * 2,h,w), 用于预测anchor的形状。
一旦训练完成,学习到的anchor会和语义特征紧密联系:

Guided Anchoring的测试流程为:
- 对于任何一层特征层,都会输出4条分支,分别是anchor的loc_preds,anchor的shape_preds,原始retinanet分支的cls_scores和bbox_preds
- 使用阈值将loc_preds预测值切分出前景区域,然后提取前景区域的shape_preds,然后结合特征图位置,concat得到4维的guided_anchors $(x,y,w,h)$
- 此时的guided_anchors就相当于retinanet里面的固定anchor了,然后和原始retinanet流程完全相同,基于guided_anchors和cls_scores、bbox_preds分支就可以得到最终的bbox预测值。
anchor的定位模块loc_preds是个二分类问题,希望学习出前景区域,采用focal loss进行训练。这个分支的设定和大部分anchor-free的做法一致:
- 首先对每个gt,利用FPN中提到的roi重映射规则,将gt映射到不同的特征图层上
- 定义中心区域和忽略区域比例,将gt落在中心区域的位置认为是正样本,忽略区域是忽略样本(模糊样本),其余区域是背景负样本

anchor的形状预测模块loc_shape的目标是给定 anchor 中心点,预测最佳的长和宽,这是一个回归问题。
- 如何确定特征图的哪些位置是正样本区域?采用ApproxMaxIoUAssigner,其核心思想是:利用原始retinanet的每个位置9个anchor设定,计算9个anchor和gt的iou,然后选出每个位置9个iou中最高的iou值,利用该iou值计算后续的MaxIoUAssigner,此时就可以得到每个特征图位置上哪些位置是正样本了。
- 正样本位置对应的shape label是什么?得到每个位置匹配的gt,那么对应的target肯定就是Gt值了。该分支的loss是bounded iou loss:


