Deformable DETR:通过可变形Transformer实现端到端目标检测.
DETR利用了Transformer通用以及强大的对相关性的建模能力,来取代anchor等一些手工设计的目标检测元素。但是依旧存在缺陷:
- 训练时间极长:相比于已有的检测器,DETR需要更久的训练才能达到收敛(500 epochs),比Faster R-CNN慢了10-20倍。这是因为在初始化阶段,DETR对于特征图中的所有像素的权重是均匀的,导致要学习的注意力权重集中在稀疏的有意义的位置这一过程需要很长时间。
- 计算复杂度高:DETR对小目标的性能很差,现代许多种检测器通常利用多尺度特征,从高分辨率特征图中检测小物体。但是高分辨率的特征图会大大提高DETR复杂度,因为自注意力计算的复杂度是像素点数目的平方。
为解决DETR收敛速度慢和计算复杂度高的问题,本文提出了Deformable DETR,结合了可变形卷积(Deformable Convolution)的稀疏空间采样的本领,以及Transformer对于相关性建模的能力。
1. Deformable Attention Module
在自注意力机制中,每个查询向量Query需要与所有键向量Key交互以计算注意力图;Deformable DETR提出了可变形注意力模块(Deformable Attention Module),每个查询向量Query的查询对象通过学习一组偏移offset得到,而注意力图通过线性变换得到。
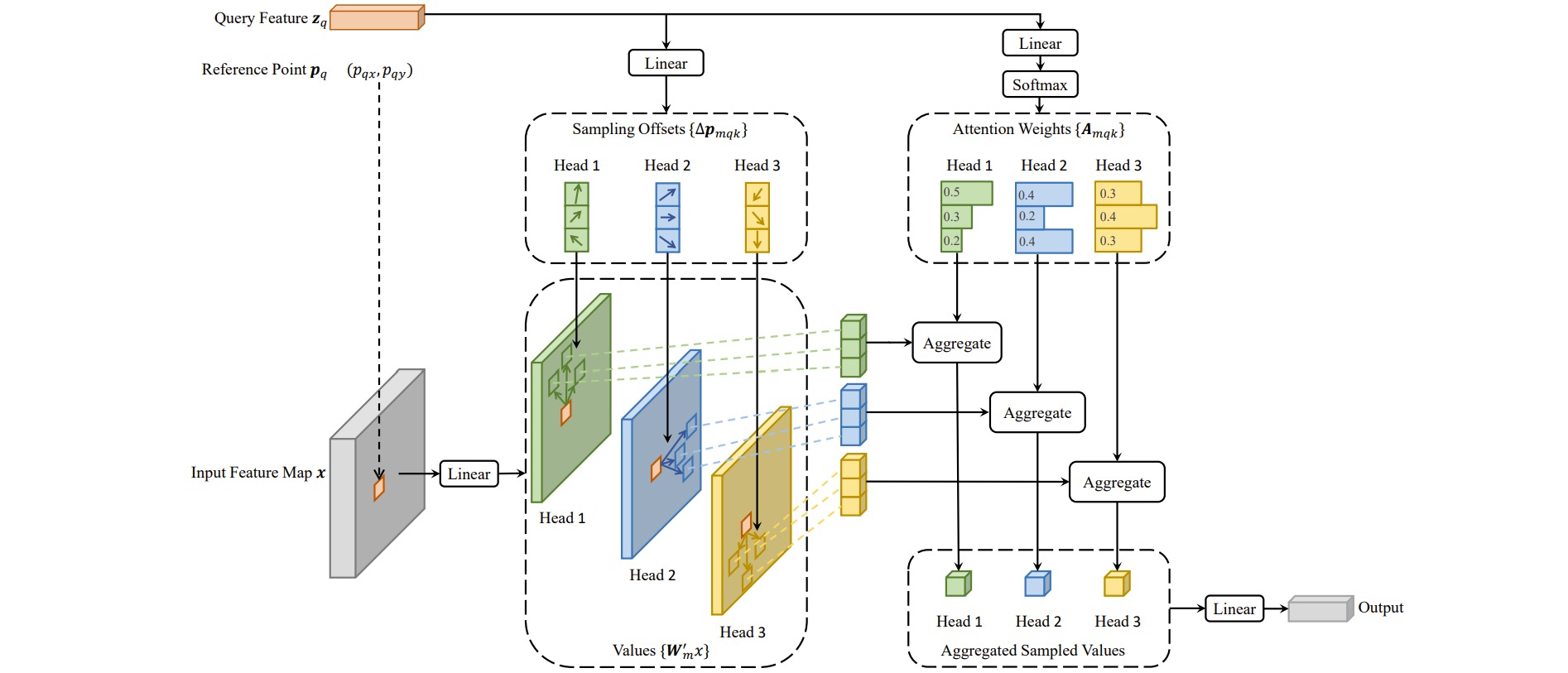
假设输入查询Query的维度是$(N_q,C)$,经过线性变换后得到$\Delta_x,\Delta_y,A$,维度均为$(N_q,MK)$。其中$\Delta_x,\Delta_y$表示关注特征位置相对参考点的偏移量offset,$A$表示学习到的注意力图。$N_q$是查询向量的数目($N_q=HW$),$M$是multi-head数量,$K$是关注特征的数量。
对输入特征$(HW,C)$做线性变换得到值矩阵$V$。根据$\Delta_x,\Delta_y$,需要为$N_q$个查询Query分别采样$K$个值,采样之后的值矩阵$V \in (N_q, K, C)$,$M$个head对应$V \in (N_q, M, K, C_M),C=MC_M$。
之后使用注意力图$A$与查询到的值矩阵$V$交互,对$K$个值进行加权平均,得到输出特征$O\in (N_q,M,C_M)$。
大多数目标检测框架受益于多尺度特征图,而Deformable Attention Module可以自然地扩展到多尺度特征图中。Multi-scale Deformable Attention Module从多尺度特征图中共采样$LK$个点,相当于对所有层均采$K$个点,融合了不同层的特征。
\[\operatorname{MSDeformAttn}\left(\boldsymbol{z}_q, \hat{\boldsymbol{p}}_q,\left\{\boldsymbol{x}^l\right\}_{l=1}^L\right)=\sum_{m=1}^M \boldsymbol{W}_m\left[\sum_{l=1}^L \sum_{k=1}^K A_{m l q k} \cdot \boldsymbol{W}_m^{\prime} \boldsymbol{x}^l\left(\phi_l\left(\hat{\boldsymbol{p}}_q\right)+\Delta \boldsymbol{p}_{m l q k}\right)\right]\]2. Deformable DETR

Deformable DETR将transformer编码器中处理特征的部分都做替换,即所有的self-attention模块都使用了Deformable Attention Module。Encoder的输入输出均为多尺度feature map,保持相同的分辨率。

Deformable DETR使用的多尺度特征一共有$4$种尺度的特征\(\{x_l\}_{l=1}^4\),所有的特征都是$256$通道。多尺度可变形注意力可以在多尺度特征图之间交换信息。作者还给不从尺度的特征加了尺度级的嵌入表示\(\{e_l\}_{l=1}^4\),随机初始化并随网络一起训练。
Deformable DETR的Decoder中有交叉注意力和自注意力两种模块,它们的Query都来自Object queries,交叉注意力的 Key来自Encoder的输出,Object queries从encoder输出的特征图中提取特征。自注意力的Key来自Object queries,Object queries彼此交互。


