(1908)一篇目标检测综述.
目标检测(object detection)旨在在一张图像中寻找所有可能目标的精确位置并对每一个目标进行分类。
本文的三个主要部分:
- 检测组件 detection components
- 学习策略 learning strategy
- 应用和基准 applications & benchmarks
本文的方法论 methodology:
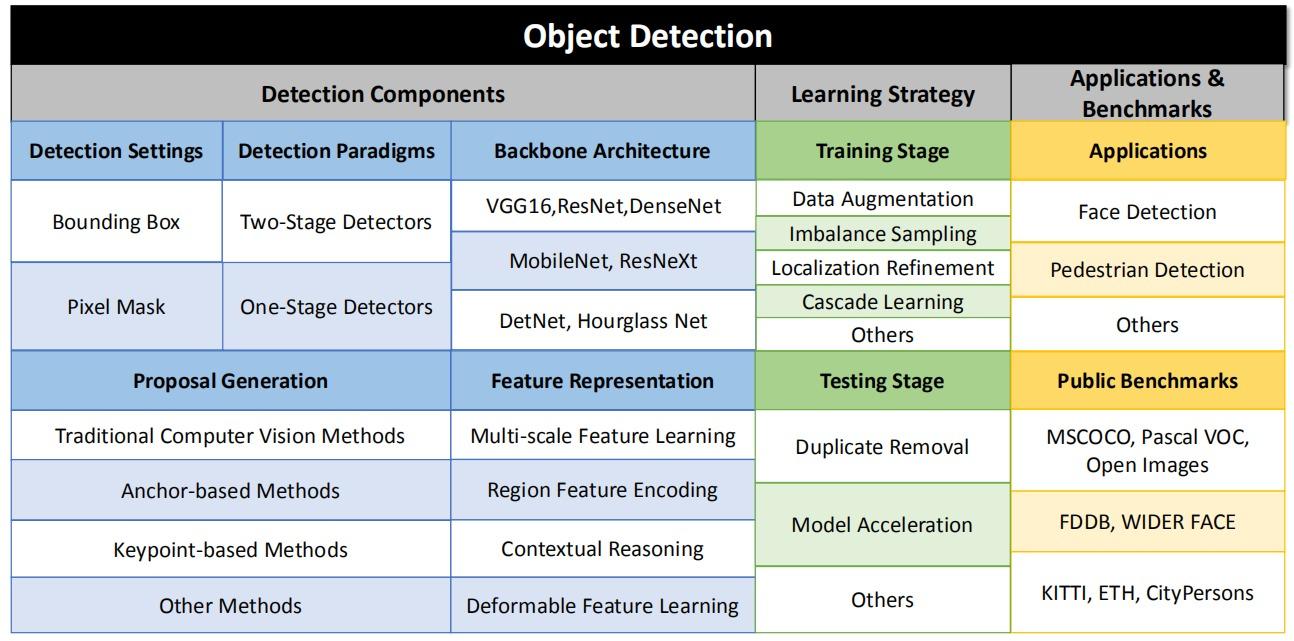
目录:
- Introduction
- Problem Settings
- Detection Components
- Learning Strategy
- Applications
- Benchmarks
- Future
1. Introduction
(1)计算机视觉的任务
计算机视觉领域的几个基础视觉任务:
- 图像分类 image classification
- 目标检测 object detection
- 语义分割 semantic segmentation
- 实例分割 instance segmentation

计算机视觉领域的几个进阶视觉任务:
- 人脸识别 face recognation
- 行人检测 pedestrian detection
- 视频分析 video detection
- 标志检测 logo detection
(2)传统的目标检测方法
传统的目标检测流水线(pipeline):
- 区域生成 proposal generation:寻找图像中可能存在目标的区域(Region of Interest,RoI);
- Sliding windows
- multi-scale images
- multi-scale windows
- 特征向量提取 feature vector extraction:使用低级的特征描述子(low-level feature descriptor)抽取特征;
- SIFT(scale invariant feature transform)
- Haar
- HOG(histogram of gradient)
- SURF(speeded up robust features)
- 区域分类 region classification:对每一个区域进行分类。
- SVM
- bagging
- cascade learning
- adaboost
传统的目标检测算法:
- DPM(deformable part-based machine)
传统目标检测的缺陷:
- 区域生成时:产生大量false positive;人工选择的window size很难匹配目标;
- 特征描述子基于低级的视觉信息,很难捕捉复杂的语义信息;
- 检测的每一步是独立设计和优化的,不能获得整个系统的全局最优解。
(3)深度学习的目标检测方法
基于深度学习的目标检测发展:

上图红色表示anchor-free方法,绿色表示AutoML方法,是未来目标检测的发展方向。
深度学习的目标检测方法优势:
- 卷积神经网络强大的特征表示 feature representation 能力;
- 可以实现端到端 end to end 的优化。
目标检测方法的分类:
- 两阶段 two-stage检测器:生成(稀疏的)感兴趣的区域并抽取特征,对每个区域进行分类;
- 单阶段 one-stage检测器:对特征映射 feature map 的每一个位置进行目标的类别预测。
2. Problem Settings
目标检测的两个主要问题:
- 识别 recognation:对图像中存在的目标进行分类;
- 定位 localization:确定图像中目标的具体位置。
两种检测设置:
- 边界框 bounding box level (bbox-level)
- 像素掩膜 pixel mask level (mask-level)
假设数据集有$N$张图像\(\{x_1,x_2,...,x_N\}\),对应标签\(\{y_1,y_2,...,y_N\}\),
记第$i$张图像内有$M_i$个目标,分别属于$C$类中的某一类:
\[y_i = \{ (c_1^i,b_1^i),(c_2^i,b_2^i),...,(c_{M_i}^i,b_{M_i}^i) \}\]其中\(c_j^i \in C\)表示类别,\(b_j^i\)表示边界框或像素掩膜参数。
设检测系统$f$的参数为$θ$,检测结果如下:
\[y_{pred}^i = \{ (c_{pred1}^i,b_{pred1}^i),(c_{pred2}^i,b_{pred2}^i),... \}\]目标检测问题的损失函数可以写作:
\[l(x,θ) = \frac{1}{N} \sum_{i=1}^{N} {l(y_{pred}^i,y_i,x_i;θ)} + \frac{λ}{2} \mid\mid θ \mid\mid^2\]评估时,定义交并比(Intersection of Union,IoU)衡量预测边界框或像素掩膜与 $ground$ $truth$ 之间的差异:
\[IoU(b_{pred},b_{gt}) = \frac{Area(b_{pred} ∩ b_{gt})}{Area(b_{pred} ∪ b_{gt})}\]最终预测只有类别预测正确并且交并比超过阈值$\Omega$才认为是正确的结果:
\[Prediction = \begin{cases} Positive, & c_{pred}=c_{gt} \text{ and } IoU(b_{pred},b_{gt}) > \Omega \\ Negative, & otherwise \end{cases}\]3. Detection Components
3.1. Detection Settings
目标检测的两种检测设置:
- 传统的目标检测:边界框定位(bbox-level)
- 实例分割:像素掩膜定位(pixel-level & mask-level)
3.2. Detection Paradigms
目标检测的两种范式:
- two-stage detector:首先生成稀疏的候选区域,再对区域进行分类预测;
- one-stage detector:把图像的任何区域都看作候选区域,区分其为目标或背景。
3.2.1 Two-stage Detectors
两阶段的目标检测把检测任务分成两步:
- 区域生成(proposal generation);
- 对生成的区域进行预测(proposal prediction)。
典型的两阶段目标检测器:
- R-CNN
- proposal generation:通过Selective Search生成稀疏的proposal集(2000个左右);
- feature extraction:使用卷积网络对resized的proposal提取4096维特征;
- region classification:用one-vs-all SVM进行区域分类;
- bbox regression:用提取的特征进行边界框的回归。
- 缺点:卷积网络重复计算耗时,各步骤独立优化,RoI选取仅使用低级图像特征。
- SPP-net
- 先通过一次卷积网络生成特征映射,在特征映射上寻找对应的proposal;
- 把proposal的cropping改为空间金字塔池化。
- 缺点:训练是多阶段的(需要额外的缓存),不能end to end,SPP层不能反向传播。
- Fast R-CNN
- 使用RoI Pooling提取区域特征(相当于单层SPP);
- 特征提取、区域分类和边界框回归end to end训练,多任务学习multi-task learning;
- Faster R-CNN
- 提出新的区域生成方法:Region Proposal Network(RPN),在特征映射上滑动窗口,在每个位置生成特征向量;
- 完全实现数据驱动的end to end学习。
- R-FCN
- 对特征映射用1×1卷积生成位置敏感得分映射position sensitive score map;
- 使用位置敏感的RoI Pooling提取特征。
- FPN
- 浅层特征映射空间信息强,语义信息弱;深层特征则相反;
- 提出了特征金字塔网络,使用多层次的特征映射。

3.2.2 One-stage Detectors
单阶段的目标检测把图像中的每个区域看作潜在的RoI,识别其为背景还是物体。
典型的单阶段目标检测器:
- OverFeat
- 用卷积网络实现滑动窗口;
- 使用多尺度的输入图像检测多尺度目标。
- 缺点:分类和回归的训练是分开的。
- YOLO:
- 把图像变成7×7的特征映射,每个栅格grid cell存储是否存在目标、边界框信息和目标的类别;
- end to end的单阶段网络,速度快;
- 缺点:每个栅格只能检测两个目标,只使用了最后一层特征映射,无法检测多尺度目标。
- SSD
- 引入了anchor;
- 在多个特征映射上预测目标;
- 使用hard negative mining避免过多negative样本。
- RetinaNet
- 引入focal loss解决类别不平衡问题.
- YOLOv2
- 用k-means预设anchor大小;
- 多尺度的训练技巧。
- CornerNet
- anchor-free的方法
- class heatmap:计算该像素属于corner的概率;
- corner offset:计算corner的偏置;
- pair embedding:把同一个物体的corner配对。

3.3. Backbone Architecture
在图像分类任务上预训练的网络能够提供更丰富的语义信息,有利于检测任务。
常用的卷积神经网络结构:
- VGG16:五组卷积层(2+2+3+3+3)和三层全连接层;
- ResNet:引入shortcut connection,把浅层特征加到深层特征上;
- DenseNet:把所有浅层特征连接到深层特征上;
- Dual Path Network(DPN):结合ResNet和Densenet,一部分特征相加,一部分特征连接;
- ResNeXt:引入组卷积,若干个通道分成一组;
- MobileNet:每个通道为一组的组卷积,适用于移动端;
- GoogLeNet:引入inception,增加模型宽度。
直接把分类任务训练的网络迁移到检测任务,会有一些问题:
- 分类任务得到的特征映射感受野较大,分辨率低;而检测任务要求相反;
- 分类任务使用单个特征映射,检测任务可以使用多个。
为检测设计的卷积神经网络:
- DetNet:使用空洞卷积增加感受野的同时保持较高的分辨率,同时使用多尺度的特征映射。
- Hourglass Network:最初为人体姿态估计设计。
3.4. Proposal Generation
Proposal是指图像中可能含有目标的区域,被用于下一步的分类和重定位。
- 两阶段的方法生成的proposal是稀疏的,仅仅包含前景或背景信息;
- 单阶段的方法生成的proposal是稠密的,把图像中每一个可能的位置看作候选区域。
区域生成的方法主要有以下四种:
- 传统的计算机视觉方法
- 基于anchor的方法
- 基于关键点的方法
- 其他方法
(1)traditional CV methods
传统计算机视觉的方法借助low-level的特征生成区域,如边缘、角点或颜色。
主要有三种实现策略:
- 计算边界框的目标得分 objectness score:对每一个可能的边界框计算是否含有目标的得分。
- 超像素融合 superpixels merging:先对图像进行分割,然后对分割区域进行融合,如Selective Search算法;
- 生成前景和背景的分割 seed segmentation,如CPMC算法。
优点:
- 算法简单
- 召回率 recall 高
缺点:
- 主要借助low-level特征
- 不能和整个检测模型一起优化
(2)anchor-based methods
基于anchor的方法,引入了基于预定义的anchor作为先验生成候选区域,从而不需要直接预测边界框,而是预测边界框的偏差。
i. Region Proposal Network(RPN)
- 在特征映射上使用3×3的卷积核滑动窗口;
- 在每个位置,使用k个anchor(不同的size和aspect ratio);
- 每一个anchor提取256维特征向量,喂入两个分支:分类层和回归层;
- 分类层给出是否为目标的得分,用来判断anchor是目标还是背景;
- 回归层给出边界框位置的修正。

ii. SSD
与RPN不同,前者分类时只判断anchor是否含有目标,具体是哪类目标需要依靠后续网络。
SSD的每个anchor区分具体是哪个目标,给出所有类别的置信概率。
iii. RefineDet
RefineDet把anchor的边界框回归分成两步:
第一步,使用手工设计的anchor,学习边界框的偏移;
第二步,使用上一步修正的anchor,学习边界框的偏移。
iv. Cascade R-CNN
使用一系列的anchor修正。
(3)keypoint-based methods
基于关键点的方法又可以分为:
- Corner-based method
- Center-based method
i. Denet
Denet是一种基于corner的方法,对于特征映射上的每一点,判断其为(top-left、top-right、bottom-left、bottom-right)corner的概率。
ii. CornerNet
CornerNet也是基于corner的方法,提出了corner pooling预测top-left和bottom-right的corner。
iii. CenterNet
CenterNet结合了corner和center的方法,一方面预测corner,一方面预测center,从而减少了FP。
(4)other methods
i. AZNet
AZNet递归的把图像划分成一系列更小的图像区域,对每个区域,AZNet计算两个值:
- zoom indicator:决定是否把这个区域继续划分
- adjacency score:计算目标得分
3.5. Feature Representation Learning
特征表示学习旨在把输入图像转变为有利于后续任务的特征映射,主要包括四种方法:
- multi-scale feature learning
- region feature encoding
- contexture reasoning
- deformable feature learning
(1)multi-scale feature learning
卷积神经网络的浅层特征:
- 丰富的空间特征 spatial-rich;
- 更高分辨率 resolution;
- 感受野较小;
- 适合检测小目标。
卷积神经网络的深层特征:
- 丰富的语义特征 semantic-rich;
- 分辨率较低;
- 更大感受野;
- 适合检测大目标。
多尺度特征学习主要有四种方法:
- Image Pyramid
- Prediction Pyramid
- Integrated Features
- Feature Pyramid

1. Image Pyramid
把图像缩放成不同的尺度,每个尺度训练一个检测器,最后将结果融合。
代表模型:Scale Normalization for Image Pyramid(SNIP)
2. Prediction Pyramid
使用多层的特征映射分别检测不同尺度的目标,代表模型:
- SSD
- Multi-scale Deep Convolutional Neural Network(MSCNN):使用转置卷积对深层特征进行上采样;
- Receptive Field Block Net(RFBNet):使用RBF block。
3. Integrated Features
结合网络不同层的特征映射构建一个新的特征映射,代表模型:
- Inside-Outside Network(ION):用RoI Pooling裁剪不同的特征,然后结合起来;
- HyperNet:使用转置卷积对深层特征进行上采样;
- Multi-scale Location-aware Kernel Representation(MLKP):捕捉各个特征的高阶统计量。
4. Feature Pyramid
结合特征融合与预测金字塔,代表模型:RPN
(2)region feature encoding
对于两阶段的检测器,区域特征编码将提取到的proposal编码为固定尺寸的特征向量。
- RoI Pooling:把proposal分成$n×n$($n$默认取$7$)的子区域,分别进行最大池化;
- RoI Warping:使用双线性插值调整proposal尺寸;
- RoI Align:使用双线性插值考虑misalignment
- Precies RoI Pooling
- Position Sensitive RoI Pooling(PSRoI Pooling):见R-FCN网络
- CoupleNet:结合RoI Pooling和PSRoI Pooling;
- Deformable RoI Pooling:学习每一个栅格的offset。
(3)contexture reasoning
有时图像中的语境信息对目标检测也很重要。语境推理主要有两种:
- global context reasoning
- region context reasoning
1. global context reasoning
- ION:用RNN编码上下文信息;
- Detection with Enriched Semantics(DES):用一个分割的mask预测上下文信息。
2. region context reasoning
- Spatial Memory Network(SMN):引入空间记忆力模块;
- Structure Inference Network(SIN):把目标检测看作图推理任务。
(4)deformable feature learning
- deformable-aware pooling
- deformable convolutional layer
4. Learning Strategy
4.1. 训练阶段
(1)Data Augmentation
- 两阶段:horizontal flip
- 单阶段:rotation、random crop、expand、color jittering
(2)Imbalance Sampling
目标检测中的正负样本不平衡问题非常显著。意味着大部分样本都是负样本(背景)。
- hard negative sampling:固定正负样本的比例,负样本使用分类损失高的hard样本。
- focal loss:越容易正确分类的样本权重越小,从而抑制其梯度:
- gradient harmonizing mechanism(GHM):抑制容易识别的样本,避免outlier
- online hard negative mining:只考虑分类的困难度,忽略类别信息
(3)Localization Refinement
边界框回归能够提高检测精度。
- smooth L1 regressor:
- LocNet:建模每个边界框的分布
- Multi-Path Network:使用多个IoU阈值不同的分类器
- Fitness-NMS:为IoU更大的区域设置更大的权重
(4)Cascade Learning
- cascade region-proposal-network and fast-rcnn(CRAFT):使用串联RPN
- RefineDet & Cascade R-CNN:使用串联边界框回归
(5)Others
- adversarial learning:使用GAN、对抗样本帮助学习
- training from scratch:不适用分类的预训练模型
- knowledge distillation:使用学生网络拟合教师网络
4.2. 测试阶段
(1)Duplicate Removal
预测结果中存在大量重复边界框或负样本。
- non maximum supression(NMS):非极大值抑制
对每一个预测类别,边界框按照置信度排序,计算得分最高的边界框$M$与其他边界框的IoU;若交并比超过阈值\(\Omega _{threshold}\),则丢弃这些边界框(得分置零):
\[Score_B = \begin{cases} Score_B, & IoU(B,M) < \Omega _{threshold} \\ 0, & IoU(B,M) ≥ \Omega _{threshold} \end{cases}\]- Soft-NMS:
对于交并比超过阈值的边界框,得分并不是直接置零,而是采用一个连续函数$F$(如线性函数、高斯函数)衰减:
\[Score_B = \begin{cases} Score_B, & IoU(B,M) < \Omega _{threshold} \\ F(IoU(B,M)), & IoU(B,M) ≥ \Omega _{threshold} \end{cases}\](2)Model Acceleration
模型加速。
- Light Head R-CNN:最后一层通道从1024调整为16
- 使用更高效的backbone:mobileNet
(3)Others
- 图像金字塔 Image Pyramid
- Horizontal Flipping
5. Applications
5.1. Face Detection
人脸检测旨在从图像中检测出人脸。
人脸检测与普通目标检测的区别:
- 人脸检测中目标的尺度范围更大;
- 目标容易受到遮挡和干扰;
- 人脸检测包含很强的结构信息;
- 人脸检测通常只有一个目标类别。
人脸检测的几个关注点:
- muti-scale feature learning:S3FD、SSH、MTCNN
- contextual information:FDNet、CMS-RCNN、PyramidBox
- loss function design:Face R-FCN
5.2. Pedestrian Detection
行人检测与普通目标检测的区别:
- 行人检测的边界框aspect radio大约是1.5,但是尺度范围变化大;
- 目标容易受到拥挤、遮挡和干扰;
- 存在更多hard negative example
6. Benchmarks
介绍一些benchmarks和评估指标 evaluation metrics 。
6.1. Generic Detection Benchmarks
用于通用目标检测的benchmarks包括:
- Pascal VOC2007:20类,训练集:验证集:测试集 = 2501:2510:5011
- Pascal VOC2012:20类,训练集:验证集:测试集 = 5717:5823:10991
- MSCOCO:80类,训练集:验证集:测试集 = 118287:5000:40670
- Open Image:共有600类、190万张图像,其中500类用于检测
- LVIS:1000类,164000张
- ImageNet:200类,不常用于目标检测
通用目标检测的评估指标:

6.2. Face Detection Benchmarks
用于人脸检测的benchmarks包括:
- WIDER FACE:32203张,训练集:验证集:测试集 = 4:1:5,有easy、medium、hard三种
- FDDB:2845张,经常被用作测试集
- PASCAL FACE:851张,经常被用作测试集
人脸检测的评估指标:

6.3. Pedestrian Detection Benchmarks
用于行人检测的benchmarks包括:
- CityPersons:5000张
- Caltech:训练集:测试集 = 42782:4024
- ETH:1804张,经常被用作测试集
- INRIA:2120张,训练集:测试集 = 1832:288
- KITTI:训练集:测试集 = 7481:7518,包括两个子类:pedestrian和cyclist,有easy、moderate、hard三种
行人检测的评估指标:

7. Future
目标检测未来的发展趋势:
- 基于anchor的方法引入了很强的先验知识,anchor-free的方法需要找到有效的区域生成策略 proposal generation;
- 如何使用更多的语境信息 contextural information;
- 基于AutoML的检测,找到低消耗的方法;
- 寻找更大的benchmarks
- low-shot目标检测,即样本很少的情况下如何检测;
- 设计检测的backbone网络
- 如何增加检测训练时的batch size;
- 增量学习 incremental learning。


