Expectation Maximization.
在求解概率分布模型$P(x ; \theta)$的参数$\theta$时,通常采用极大似然估计方法;其中$x$被称为观测变量(observable variable)。给定数据后极大化观测变量$x$关于参数$\theta$的对数似然函数:
\[L(\theta) = \log P(x ; \theta)\]若概率模型还包含隐变量(latent variable) $z$,则观测变量$x$和隐变量$z$对应的数据总称为完全数据(complete data),对应的对数似然为:
\[L(\theta) = \log P(x ; \theta) = \log \int_{z}^{} P(x,z ; \theta) dz\]由于隐变量的不可观测性,上式是intractable的,因为对数函数中包含积分项;需要采用近似算法处理。
期望最大(expectation maximization,EM)算法是用于解决含有隐变量的概率模型的极大似然估计方法,是一种迭代计算的数值方法。
本文目录:
- 使用条件概率和KL散度推导EM算法
- 使用边缘分布和Jenson不等式推导EM算法
- EM算法的几何解释:近似曲线逼近
- EM算法的收敛性证明
- 广义EM算法
1. 使用条件概率和KL散度推导EM算法
当概率模型$P(x ; \theta)$含有隐变量$z$时,对其对数似然函数做如下变换:
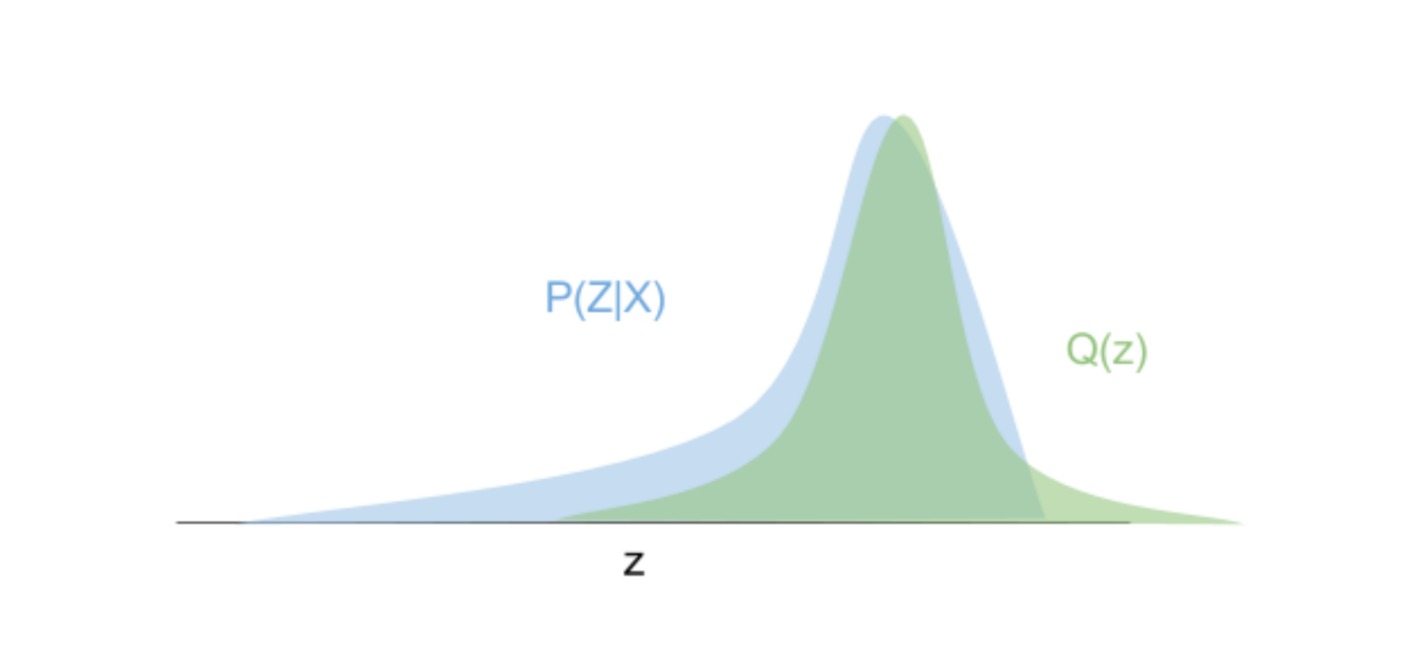
\[\begin{aligned} \log P(x ; \theta) &= \log \frac{P(x,z ; \theta)}{P(z|x ; \theta)} \\ &= \log P(x,z ; \theta) - \log P(z|x ; \theta) \\ &= \log \frac{P(x,z ; \theta)}{Q(z)} - \log \frac{P(z|x ; \theta)}{Q(z)} \end{aligned}\]上式即使已知联合分布$P(x,z ; \theta)$,其条件分布$P(z|x ; \theta)$也是未知的;引入一个新的分布$Q(z)$近似该分布。上式两端对$Q(z)$求期望:
\[\begin{aligned} \text{左端} &= \int_{z}^{} Q(z) \log P(x ; \theta) dz = \log P(x ; \theta) \int_{z}^{} Q(z) dz = \log P(x ; \theta) \\ \text{右端} &= \int_{z}^{} Q(z) \log\frac{P(x,z ; \theta)}{Q(z)} dz - \int_{z}^{} Q(z) \log\frac{P(z|x ; \theta)}{Q(z)} dz \\ &= \text{ELBO} + \text{KL}(Q(z) || P(z|x ; \theta)) \end{aligned}\]上式中KL散度是一个不小于零的值;ELBO为证据下界(evidence lower bound),是对数似然函数的一个下界;即:
\[\log P(x ; \theta) = \text{ELBO} + \text{KL}(Q || P) ≥ \text{ELBO}\]极大似然估计的原目标函数为:
\[\theta_{\text{MLE}} = \mathop{\arg \max}_{\theta} \log P(x ; \theta)\]假设对于第$t$轮计算得到的$\theta^{(t)}$,KL散度可以忽略,即$\text{KL}(Q(z) | | P(z|x ; \theta^{(t)})) ≈ 0$,此时$Q(z) ≈ P(z|x ; \theta^{(t)})$,且目标函数近似替代为:
\[\mathop{\arg \max}_{\theta} \log P(x ; \theta) ≈ \mathop{\arg \max}_{\theta} \text{ELBO}\]此时ELBO可以表示为:
\[\begin{aligned} \text{ELBO} &= \int_{z}^{} Q(z) \log\frac{P(x,z ; \theta)}{Q(z)} dz \\ &= \int_{z}^{} P(z|x ; \theta^{(t)}) \log\frac{P(x,z ; \theta)}{P(z|x ; \theta^{(t)})} dz \\ &= \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz - \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(z|x ; \theta^{(t)}) dz \end{aligned}\]注意到上式右端只有第一项包含参数$\theta$,因此最大化ELBO等价于最大化第一项,即:
\[\begin{aligned} \theta^{(t+1)} &= \mathop{\arg \max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\ &= \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log P(x,z ; \theta)] \end{aligned}\]上式即为期望最大算法的表达式。
2. 使用边缘分布和Jenson不等式推导EM算法
当概率模型$P(x ; \theta)$含有隐变量$z$时,对其对数似然函数做如下变换:
\[\begin{aligned} \log P(x ; \theta) &= \log \int_{z}^{} P(x,z ; \theta) dz \\&= \log \int_{z}^{} \frac{P(x,z ; \theta)}{Q(z)} Q(z) dz \\ &= \log \Bbb{E}_{Q(z)} [\frac{P(x,z ; \theta)}{Q(z)}] \end{aligned}\]引入一个新的分布$Q(z)$,将上式表示成期望的形式,由于$\log$函数是凹函数(concave),由Jenson不等式:
\[\log \Bbb{E}_{Q(z)} [\frac{P(x,z ; \theta)}{Q(z)}] ≥ \Bbb{E}_{Q(z)} [\log \frac{P(x,z ; \theta)}{Q(z)}]\]上式等号成立当且仅当$\frac{P(x,z ; \theta)}{Q(z)}$为常数$C$,此时$P(x,z ; \theta)=CQ(z)$,两端对$z$取积分得$C=P(x; \theta)$,故$Q(z)=\frac{P(x,z ; \theta)}{P(x; \theta)}=P(z|x ; \theta)$。
极大似然估计的原目标函数为:
\[\theta_{\text{MLE}} = \mathop{\arg \max}_{\theta} \log P(x ; \theta)\]假设对于第$t$轮计算得到的$\theta^{(t)}$,Jenson不等式可取等号,即$Q(z)=P(z|x ; \theta^{(t)})$,此时目标函数近似替代为:
\[\begin{aligned} \mathop{\arg \max}_{\theta} \log P(x ; \theta) =& \mathop{\arg \max}_{\theta} \Bbb{E}_{Q(z)} [\log \frac{P(x,z ; \theta)}{Q(z)}] \\ =& \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})} [\log \frac{P(x,z ; \theta)}{P(z|x ; \theta^{(t)})}] \\ =& \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})} [\log P(x,z ; \theta)] \\ &-\mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})} [\log P(z|x ; \theta^{(t)})] \end{aligned}\]注意到上式右端只有第一项包含参数$\theta$,因此最大化目标函数等价于:
\[\theta^{(t+1)} = \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})} [\log P(x,z ; \theta)]\]3. EM算法的几何解释:近似曲线逼近
EM算法的表达式如下:
\[\begin{aligned} \theta^{(t+1)} &= \mathop{\arg \max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\ &= \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log P(x,z ; \theta)] \end{aligned}\]EM算法在迭代时分成两步。第一步(E-step),计算联合分布的对数似然函数$\log P(x,z ; \theta)$关于给定参数$\theta^{(t)}$下的条件分布$P(z|x ; \theta^{(t)})$的期望;第二步(M-step),计算期望的最大值。参数的初值可以任意选择,但需注意EM算法对初值是敏感的。

上图给出了EM算法的直观解释。对数似然函数表示为曲线$L(\theta)$,该曲线是无法直接求解的。因此在每次迭代$\theta^{(t)}$时寻找对数似然函数的一个下界(即ELBO,表示为$B(\theta,\theta^{(t)})$),通过极大化该下界来近似极大化对数似然。由于$L(\theta)≥B(\theta,\theta^{(t)})$,保证每次迭代时对数似然都是增加的。
4. EM算法的收敛性证明
下面说明极大似然估计的收敛性等价于期望最大算法的收敛性。原问题的极大似然估计的目标函数为:
\[\theta_{\text{MLE}} = \mathop{\arg \max}_{\theta} \log P(x ; \theta)\]注意到$P(x ; \theta)≤1$,因此函数$\log P(x ; \theta)$有上界;只需要证明该函数对于参数$\theta$是单调的,则可说明该目标函数是收敛的。即证:
\[\log P(x ; \theta^{(t+1)}) ≥ \log P(x ; \theta^{(t)})\]对目标函数做一些变换:
\[\begin{aligned} \log P(x ; \theta) &= \log \frac{P(x,z ; \theta)}{P(z|x ; \theta)} \\ &= \log P(x,z ; \theta) - \log P(z|x ; \theta) \end{aligned}\]上式两端对$P(z|x ; \theta^{(t)})$求期望:
\[\begin{aligned} \text{左端} &= \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x ; \theta) dz = \log P(x ; \theta) \int_{z}^{} P(z|x ; \theta^{(t)}) dz = \log P(x ; \theta) \\ \text{右端} &= \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz - \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(z|x ; \theta) dz \end{aligned}\]若记:
\[Q(\theta) = \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\ H(\theta) = \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(z|x ; \theta) dz\]则有:
\[\log P(x ; \theta) = Q(\theta) - H(\theta)\]若证$\log P(x ; \theta^{(t+1)}) ≥ \log P(x ; \theta^{(t)})$,不妨证$Q(\theta^{(t+1)}) ≥ Q(\theta^{(t)})$和$H(\theta^{(t+1)}) ≤ H(\theta^{(t)})$。
⚪ 证明 $Q(\theta^{(t+1)}) ≥ Q(\theta^{(t)})$
由于$Q(\theta)$恰好是期望最大算法的第一步得到的期望值,即:
\[\begin{aligned} \theta^{(t+1)} &= \mathop{\arg \max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\&= \mathop{\arg \max}_{\theta} Q(\theta) \end{aligned}\]因此$\theta^{(t+1)}$是使得$Q(\theta)$取得最大值的参数:
\[\begin{aligned} Q(\theta^{(t+1)}) &= \mathop{\max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\ &≥ \mathop{\max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta^{(t)}) dz \\&= Q(\theta^{(t)}) \end{aligned}\]⚪ 证明 $H(\theta^{(t+1)}) ≤ H(\theta^{(t)})$
\[\begin{aligned} H(\theta^{(t+1)}) - H(\theta^{(t)}) =& \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(z|x ; \theta^{(t+1)}) dz \\&- \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(z|x ; \theta^{(t)}) dz \\ =& \int_{z}^{} P(z|x ; \theta^{(t)}) \log\frac{P(z|x ; \theta^{(t+1)})}{P(z|x ; \theta^{(t)})} dz \\ =& \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log\frac{P(z|x ; \theta^{(t+1)})}{P(z|x ; \theta^{(t)})}] \\ &\text{(由Jenson不等式)} \\ ≤& \log\Bbb{E}_{P(z|x ; \theta^{(t)})}[\frac{P(z|x ; \theta^{(t+1)})}{P(z|x ; \theta^{(t)})}] \\ = &\log \int_{z}^{} P(z|x ; \theta^{(t)}) \frac{P(z|x ; \theta^{(t+1)})}{P(z|x ; \theta^{(t)})} dz \\ =& \log \int_{z}^{} P(z|x ; \theta^{(t+1)}) dz\\ =& \log 1 = 0 \end{aligned}\]5. 广义EM算法
EM算法的表达式如下:
\[\begin{aligned} \theta^{(t+1)} &= \mathop{\arg \max}_{\theta} \int_{z}^{} P(z|x ; \theta^{(t)}) \log P(x,z ; \theta) dz \\ &= \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log P(x,z ; \theta)] \end{aligned}\]在迭代中分为两步执行:
\[\begin{aligned} \text{E-step:} &P(z|x ; \theta^{(t)}) → \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log P(x,z ; \theta)] \\\text{M-step:} &\theta^{(t+1)} = \mathop{\arg \max}_{\theta} \Bbb{E}_{P(z|x ; \theta^{(t)})}[\log P(x,z ; \theta)] \end{aligned}\]上述算法要求条件概率$P(z|x ; \theta^{(t)})$是可求的。若该条件概率不可求,则仍将对数似然函数看作ELBO和KL散度之和:
\[\begin{aligned} \log P(x ; \theta) &= \int_{z}^{} Q(z) log\frac{P(x,z ; \theta)}{Q(z)} dz - \int_{z}^{} Q(z) log\frac{P(z|x ; \theta)}{Q(z)} dz \\ &= \text{ELBO}(Q,\theta) + \text{KL}(Q(z) || P(z|x ; \theta)) \end{aligned}\]此时可将$Q(z)$也看做未知量,在迭代求解时与参数$\theta$一起求解。即给定$\hat{\theta}$时,有:
\[\hat{Q} = \mathop{\arg \min}_{Q} \text{KL}(Q(z) || P(z|x ; \theta)) = \mathop{\arg \max}_{Q} \text{ELBO}(Q,\hat{\theta})\]给定$\hat{Q}$时,有:
\[\hat{\theta} = \mathop{\arg \max}_{\theta} \text{ELBO}(\hat{Q},\theta)\]上述算法被称作广义期望最大(generalized expectation maximization,GEM)算法,也被称作极大-极大(maximization-maximization)算法,算法流程如下:
\[\begin{aligned} \text{E-step:} &Q^{(t+1)} = \mathop{\arg \max}_{Q} \text{ELBO}(Q,\theta^{(t)}) \\ \text{M-step:}& \theta^{(t+1)} = \mathop{\arg \max}_{\theta} \text{ELBO}(Q^{(t+1)},\theta) \end{aligned}\]